The theory of concurrent programming
来由
借助数据库和类似Tomcat中间件而不用写并发程序的时代已经过去了。
举个例子,Java里的synchronized、wait()/notify() 相关的知识很琐碎,看懂难,会用更难。
但实际上 synchronized、wait()、notify() 不过是操作系统领域里管程模型的一种实现而已,Java SDK 并发包里的条件变量 Condition 也是管程里的概念,如果站在管程这个理论模型的高度而不是单独理解,用起来就得心应手了。
管程
一种解决并发问题的模型,与信号量在逻辑上是等价的,但管程更易用
很多语言都支持管程。
Java SDK并发包乃是并发大师 Doug Lea 出品,其章法在哪里呢?
并发编程其实就是三个核心问题【且Java SDK并发包大部分内容都是按照这三个维度组织的】:
- 分工
- 如何高效地拆解任务并分配给线程
- E.g.:Fork/Join框架
- 同步
- 线程之间如何协作
- E.g.:CountDownLatch
- 互斥
- 保证同一时刻只允许一个线程访问共享资源
- E.g.:可重入锁
Java SDK仅仅是针对并发问题开发出来的工具而已
并发编程BUG的源头
CPU、内存、I/O设备三者中间存在一个核心矛盾就是速度差异
CPU 一天对内存一年;内存一天对I/O设备十年
为了合理利用 CPU 的高性能,平衡这三者的速度差异,计算机体系结构、操作系统、编译程序都做出了贡献:
- CPU 增加了缓存,以均衡与内存的速度差异;
- 操作系统增加了进程、线程,以分时复用 CPU,进而均衡 CPU 与 I/O 设备的速度差异;
- 编译程序优化指令执行次序,使得缓存能够得到更加合理地利用。
正是这些造就了并发编程的BUG神出鬼没
缓存导致的可见性问题
一个线程对共享变量的修改,另外一个线程能够立刻看到,我们称为可见性
单核时代,所有的线程都是在一颗 CPU 上执行,CPU 缓存与内存的数据一致性容易解决。因为所有线程都是操作同一个 CPU 的缓存,一个线程对缓存的写,对另外一个线程来说一定是可见的。
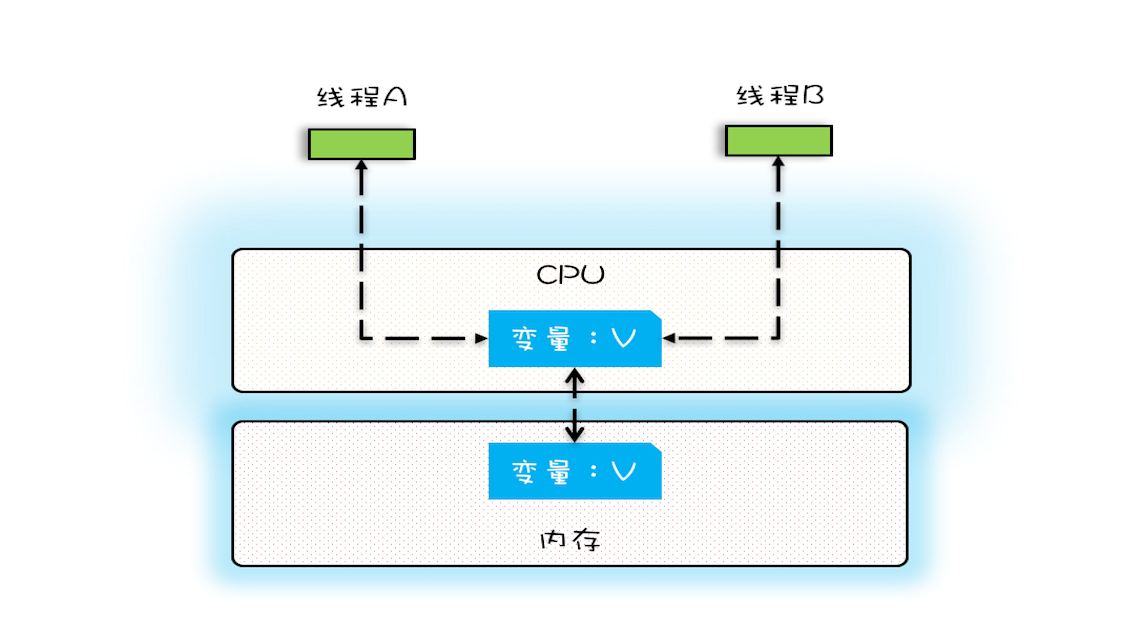
多核时代,每颗 CPU 都有自己的缓存,这时 CPU 缓存与内存的数据一致性就没那么容易解决了,当多个线程在不同的 CPU 上执行时,这些线程操作的是不同的 CPU 缓存。
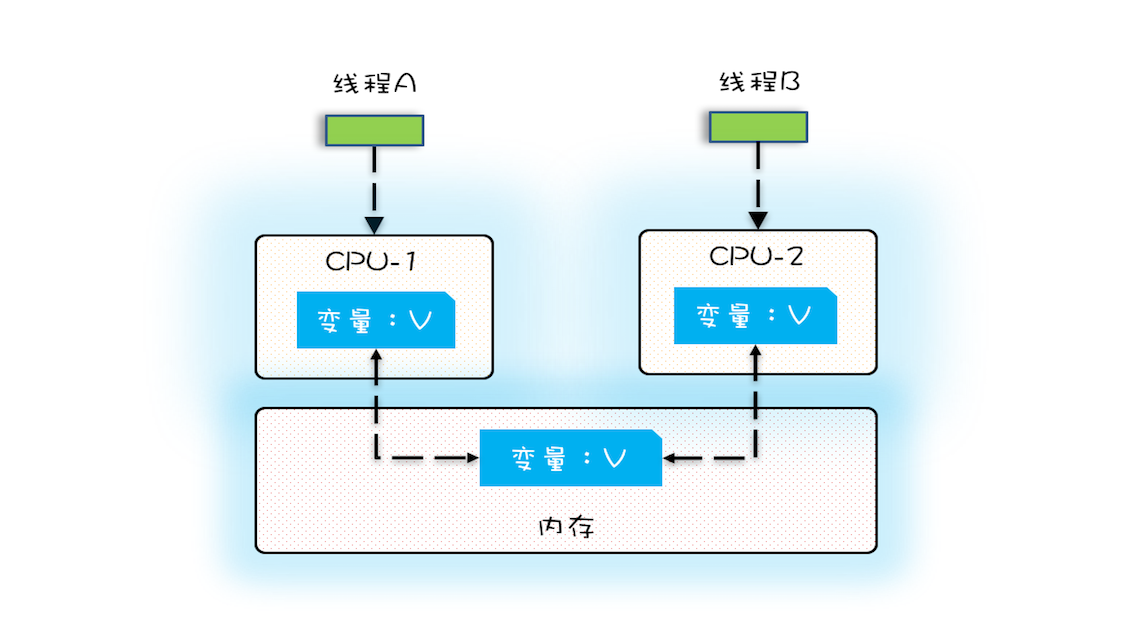
验证
多核场景下的可见性问题
1 | public class Test1 { |
其运行结果并非我们的直觉2000,而是一个10000到20000之间的随机数。
假设线程 A 和线程 B 同时开始执行,那么第一次都会将 count=0 读到各自的 CPU 缓存里,执行完 count+=1 之后,各自 CPU 缓存里的值都是 1,同时写入内存后,我们会发现内存中是 1,而不是我们期望的 2。之后由于各自的 CPU 缓存里都有了 count 的值,两个线程都是基于 CPU 缓存里的 count 值来计算,所以导致最终 count 的值都是小于 20000 的。这就是缓存的可见性问题。
循环 10000 次 count+=1 操作如果改为循环 1 亿次,你会发现效果更明显,最终 count 的值接近 1 亿,而不是 2 亿。如果循环 10000 次,count 的值接近 20000,原因是两个线程不是同时启动的,有一个时差。
线程切换带来的原子性问题
I/O太慢,所以早期系统发明了多进程
操作系统允许某个进程执行一小段时间,例如 50 毫秒,过了 50 毫秒操作系统就会重新选择一个进程来执行(我们称为“任务切换”),这个 50 毫秒称为“时间片”。【可参考CPU Sched】
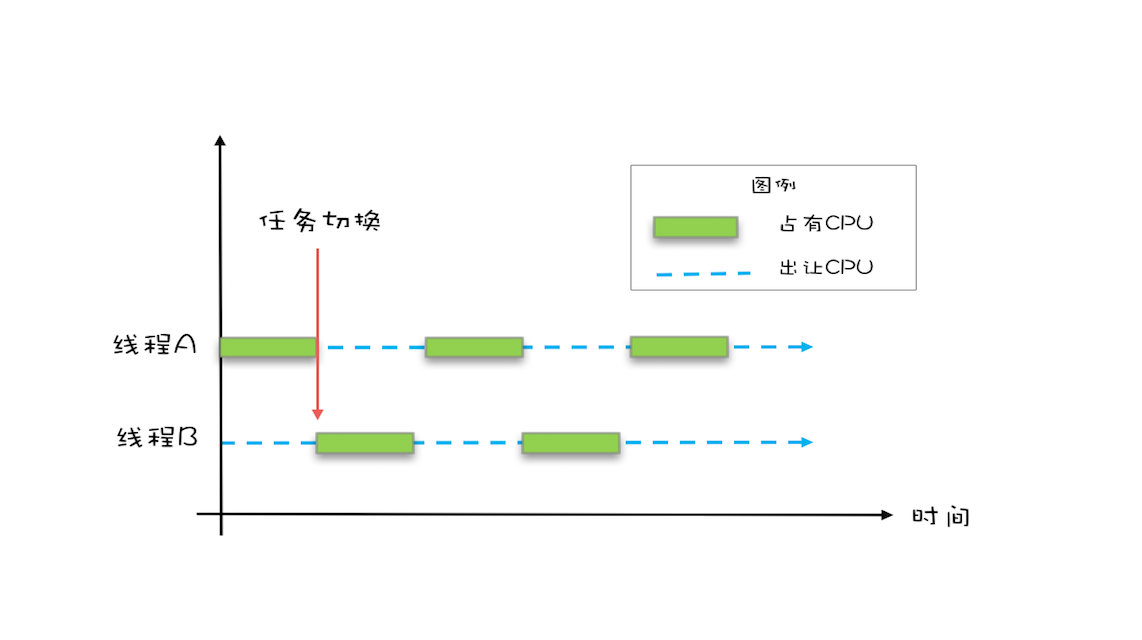
在一个时间片内,如果一个进程进行一个 IO 操作,例如读个文件,这个时候该进程可以把自己标记为“休眠状态”并出让 CPU 的使用权,待文件读进内存,操作系统会把这个休眠的进程唤醒,唤醒后的进程就有机会重新获得 CPU 的使用权了。
这里的进程在等待 IO 时之所以会释放 CPU 使用权,是为了让 CPU 在这段等待时间里可以做别的事情,这样一来 CPU 的使用率就上来了;此外,如果这时有另外一个进程也读文件,读文件的操作就会排队,磁盘驱动在完成一个进程的读操作后,发现有排队的任务,就会立即启动下一个读操作,这样 IO 的使用率也上来了。
支持多进程分时复用在操作系统发展史上有里程碑意义
早期的操作系统基于进程来调度 CPU,不同进程间是不共享内存空间的,所以进程要做任务切换就要切换内存映射地址,而一个进程创建的所有线程,都是共享一个内存空间的,所以线程做任务切换成本就很低了。
现代的操作系统都基于更轻量的线程来调度,现在我们提到的“任务切换”都是指“线程切换”。
Java并发程序都是基于多线程的,自然会涉及到任务切换,任务切换的时机大多数都是在时间片结束的时候,高级语言里一条语句往往需要多条CPU指令完成。
E.g.:count += 1
- 指令 1:首先,需要把变量 count 从内存加载到 CPU 的寄存器;
- 指令 2:之后,在寄存器中执行 +1 操作;
- 指令 3:最后,将结果写入内存(缓存机制导致可能写入的是 CPU 缓存而不是内存)。
操作系统做任务切换,可以在任何一条CPU指令执行完,对于上述三条指令,我们假设count = 0,如果线程A在指令1执行完后做线程切换,线程A和线程B按照图示执行,那么就会两个线程都执行了count+=1的操作,得到1而不是2。
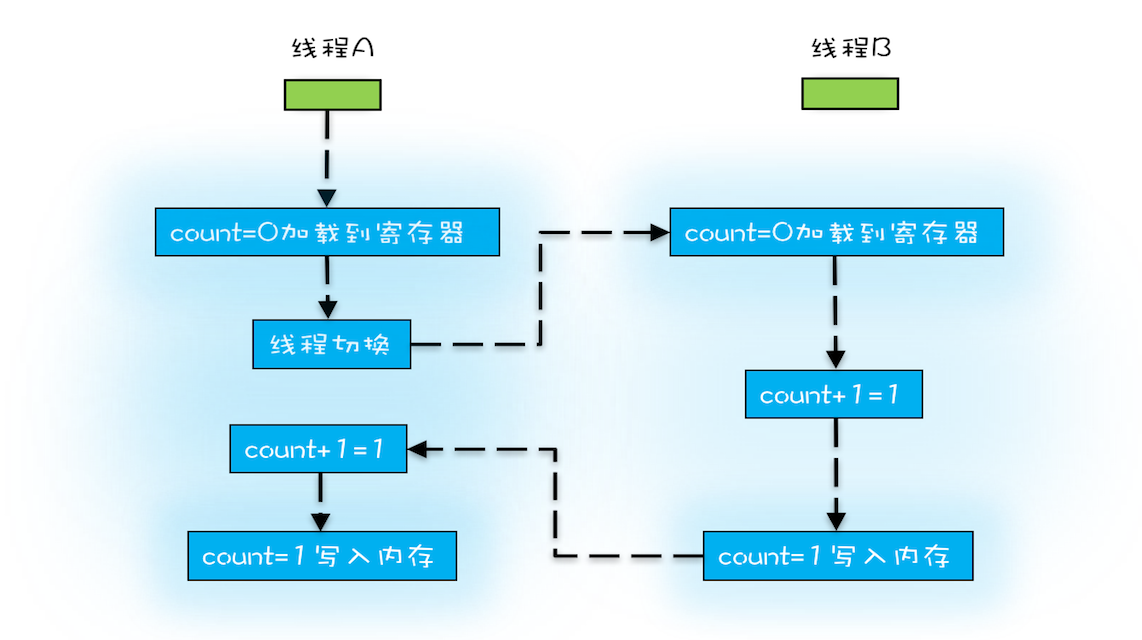
我们潜意识里面觉得 count+=1 这个操作是一个不可分割的整体,就像一个原子一样,线程的切换可以发生在 count+=1 之前,也可以发生在 count+=1 之后,但就是不会发生在中间。
我们把一个或者多个操作在 CPU 执行的过程中不被中断的特性称为原子性。CPU 能保证的原子操作是 CPU 指令级别的,而不是高级语言的操作符,这是违背我们直觉的地方。因此,很多时候我们需要在高级语言层面保证操作的原子性。
编译优化带来的有序性问题
有序性指的是程序按照代码的先后顺序执行
编译器为了优化性能,有时候会改变程序中语句的先后顺序,例如程序中:“a=6;b=7;”编译器优化后可能变成“b=7;a=6;”。
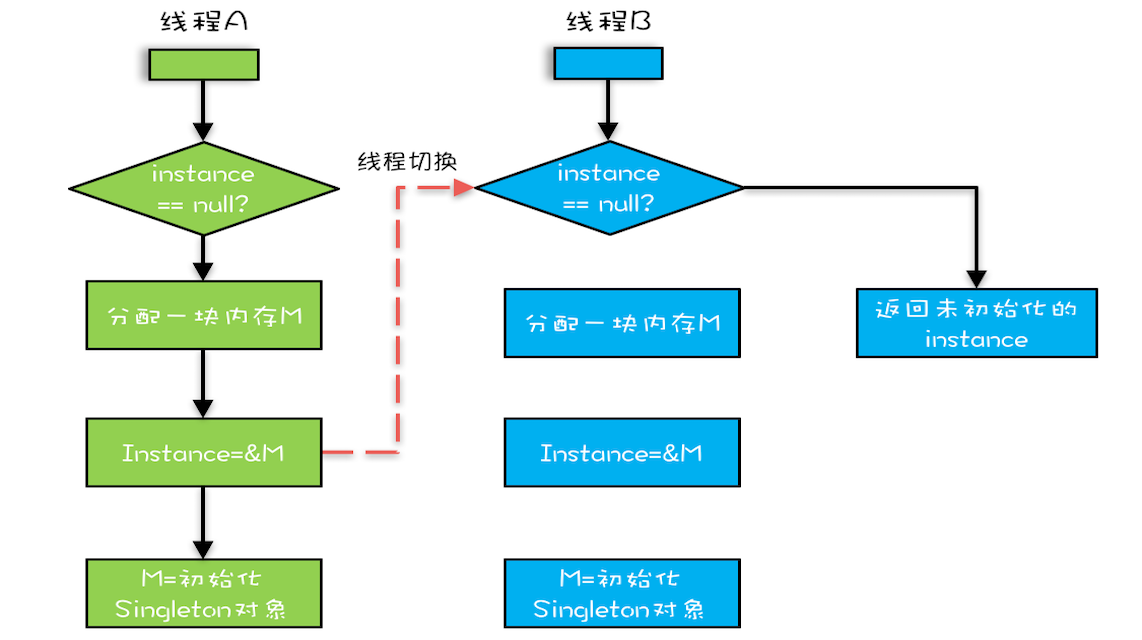
Java领域里有一个经典的案例就是利用双重检查创建单例对象
1 | /** |
假设有两个线程 A、B 同时调用 getInstance() 方法,他们会同时发现 instance == null ,于是同时对 Singleton.class 加锁,此时 JVM 保证只有一个线程能够加锁成功(假设是线程 A),另外一个线程则会处于等待状态(假设是线程 B);
线程 A 会创建一个 Singleton 实例,之后释放锁,锁释放后,线程 B 被唤醒,线程 B 再次尝试加锁,此时是可以加锁成功的,加锁成功后,线程 B 检查 instance == null 时会发现,已经创建过 Singleton 实例了,所以线程 B 不会再创建一个 Singleton 实例。
我们的直觉是这样,但实际上,getInstance() 方法并不完美,问题就出现在new操作上,
我们认为的new操作应该是:① 分配一块内存M;② 在内存上初始化Singleton对象;③ 然后M的地址赋值给instance变量
但是实际上优化后的执行路径是:
- 分配一块内存 M;
- 将 M 的地址赋值给 instance 变量;
- 最后在内存 M 上初始化 Singleton 对象。
所以就会出现:我们假设线程 A 先执行 getInstance() 方法,当执行完指令 2 时恰好发生了线程切换,切换到了线程 B 上;如果此时线程 B 也执行 getInstance() 方法,那么线程 B 在执行第一个判断时会发现 instance != null ,所以直接返回 instance,而此时的 instance 是没有初始化过的,如果我们这个时候访问 instance 的成员变量就可能触发空指针异常。
问题
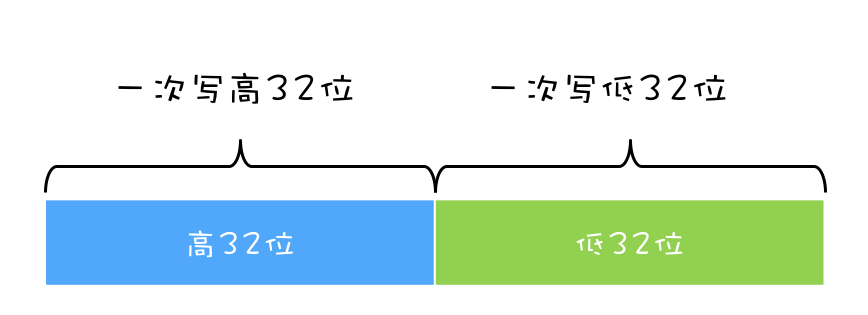
Q:32位机器上对long型变量进行加减操作存在并发隐患。
A:long类型64位,在32位的机器上,对long类型的数据操作通常需要多条指令组合出来,无法保证原子性。
原因就是文章里的bug源头之二:线程切换带来的原子性问题。
非volatile类型的long和double型变量是8字节64位的,32位机器读或写这个变量时得把人家咔嚓分成两个32位操作,可能一个线程读了某个值的高32位,低32位已经被另一个线程改了。所以官方推荐最好把long\double 变量声明为volatile或是同步加锁synchronize以避免并发问题。Reference
解决问题
解决可见性和有序性问题
Java 内存模型
Java 内存模型规范了 JVM 如何提供按需禁用缓存和编译优化的方法。具体来说,这些方法包括 volatile、synchronized 和 final 三个关键字,以及六项 Happens-Before 规则。
我们都知道导致可见性的原因是缓存,导致有序性的原因是编译优化,那解决可见性、有序性最直接的办法就是禁用缓存和编译优化。
但是这样虽然问题解决了,但是程序的性能达不到最佳
合理的方案应该是按需禁用缓存以及编译优化,所谓“按需禁用”其实就是指按照程序员的要求来禁用。所以,为了解决可见性和有序性问题,只需要提供给程序员按需禁用缓存和编译优化的方法即可。
volatile
禁用CPU缓存
E.g.:声明一个 volatile 变量 volatile int x = 0,其代表的含义:对这个变量的读写,不能使用 CPU 缓存,必须从内存中读取或者写入。
1 | /** |
在Java1.5时对volatile语义进行了增强,通过Happens-Before 规则的方法。
Happens-Before 规则
前面一个操作的结果对后续操作是可见的。
约束了编译器的优化行为,虽然允许编译器优化,但是要求优化后一定遵守规则
程序的顺序性规划
在一个线程中,按照程序顺序,前面的操作 Happens-Before 于后续的任意操作。
E.g.:代码 “x = 42;” Happens-Before 于代码 “v = true;”。
符合单线程思维:程序前面对某个变量的修改一定是对后续操作可见的
volatile 变量规则
对一个 volatile 变量的写操作, Happens-Before 于后续对这个 volatile 变量的读操作。
对一个 volatile 变量的写操作相对于后续对这个 volatile 变量的读操作可见,这怎么看都是禁用缓存的意思啊,貌似和 1.5 版本以前的语义没有变化啊?如果单看这个规则,的确是这样,但是如果我们关联一下规则 3,就有点不一样的感觉了。
传递性
如果 A Happens-Before B,且 B Happens-Before C,那么 A Happens-Before C。
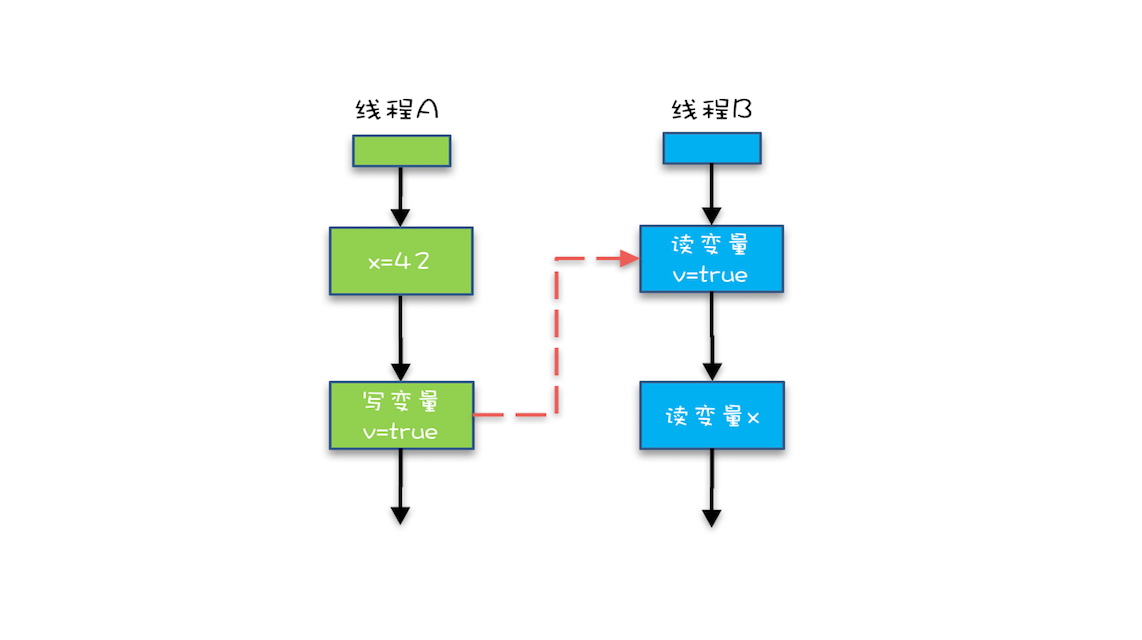
- “x=42” Happens-Before 写变量 “v=true” ,这是规则 1 的内容;
- 写变量“v=true” Happens-Before 读变量 “v=true”,这是规则 2 的内容 。
再根据这个传递性规则,我们得到结果:“x=42” Happens-Before 读变量“v=true”。这意味着什么呢?
如果线程 B 读到了“v=true”,那么线程 A 设置的“x=42”对线程 B 是可见的。也就是说,线程 B 能看到 “x == 42” ,有没有一种恍然大悟的感觉?这就是 1.5 版本对 volatile 语义的增强,这个增强意义重大,1.5 版本的并发工具包(java.util.concurrent)就是靠 volatile 语义来搞定可见性的,
管程中锁的规则
对一个锁的解锁 Happens-Before 于后续对这个锁的加锁。
我们前面提到过:管程是一种通用的同步原语,在 Java 中指的就是 synchronized,synchronized 是 Java 里对管程的实现。
管程中的锁在 Java 里是隐式实现的,例如下面的代码,在进入同步块之前,会自动加锁,而在代码块执行完会自动释放锁,加锁以及释放锁都是编译器帮我们实现的。
1 | synchronized (this) { //此处自动加锁 |
假设 x 的初始值是 10,线程 A 执行完代码块后 x 的值会变成 12(执行完自动释放锁),线程 B 进入代码块时,能够看到线程 A 对 x 的写操作,也就是线程 B 能够看到 x==12。
线程start()规则
关于线程启动的,主线程 A 启动子线程 B 后,子线程 B 能够看到主线程在启动子线程 B 前的操作。
如果线程 A 调用线程 B 的 start() 方法(即在线程 A 中启动线程 B),那么该 start() 操作 Happens-Before 于线程 B 中的任意操作。具体可参考下面示例代码。
1 | Thread B = new Thread(()->{ |
线程 join() 规则
关于线程等待的,主线程 A 等待子线程 B 完成(主线程 A 通过调用子线程 B 的 join() 方法实现),当子线程 B 完成后(主线程 A 中 join() 方法返回),主线程能够看到子线程的操作。
看到:指的是对共享变量的操作
如果在线程 A 中,调用线程 B 的 join() 并成功返回,那么线程 B 中的任意操作 Happens-Before 于该 join() 操作的返回。
1 | Thread B = new Thread(()->{ |
final
我们提到volatile为禁用缓存以及编译优化,final可以告诉编译器优化得更好一些。
final修饰变量时,初衷是告诉编译器,这个变量生而不变,可劲优化。
问题类似于上一期提到的利用双重检查方法创建单例,构造函数的错误重排导致线程可能看到 final 变量的值会变化。详细的案例可以参考Reference
在 1.5 以后 Java 内存模型对 final 类型变量的重排进行了约束。现在只要我们提供正确构造函数没有“逸出”,就不会出问题了。
1 | /** |
Reference:

Q: 有一个共享变量 abc,在一个线程里设置了 abc 的值 abc=3,有哪些办法可以让其他线程能够看到abc==3?
A:
- 声明共享变量abc,并使用volatile关键字修饰abc
- 声明共享变量abc,在synchronized关键字对abc的赋值代码块加锁,由于Happen-before管程锁的规则,可以使得后续的线程可以看到abc的值。
- A线程启动后,使用A.JOIN()方法来完成运行,后续线程再启动,则一定可以看到abc==3
解决原子性问题
一个或者多个操作在CPU执行的过程中不被中断的特性,称为原子性
原子性问题的源头是线程切换,而操作系统做线程切换是依CPU中断的,所以禁止CPU发生中断就能够禁止线程切换。
这样的方案在单核CPU上可行,但是对于多核CPU,例如前面的问题,long型变量时64位,在32位CPU上执行写操作会被拆分成两次操作(写高32位和写低32位)
在单核 CPU 场景下,同一时刻只有一个线程执行,禁止 CPU 中断,意味着操作系统不会重新调度线程,也就是禁止了线程切换,获得 CPU 使用权的线程就可以不间断地执行,所以两次写操作一定是:要么都被执行,要么都没有被执行,具有原子性。
但是在多核场景下,同一时刻,有可能有两个线程同时在执行,一个线程执行在 CPU-1 上,一个线程执行在 CPU-2 上,此时禁止 CPU 中断,只能保证 CPU 上的线程连续执行,并不能保证同一时刻只有一个线程执行,如果这两个线程同时写 long 型变量高 32 位的话,那就有可能出现我们开头提及的诡异 Bug 了。
“同一时刻只有一个线程执行”这个条件非常重要,我们称之为互斥。如果我们能够保证对共享变量的修改是互斥的,那么,无论是单核 CPU 还是多核 CPU,就都能保证原子性了。
简易锁模型
谈到互斥,首要的解决方案肯定是锁
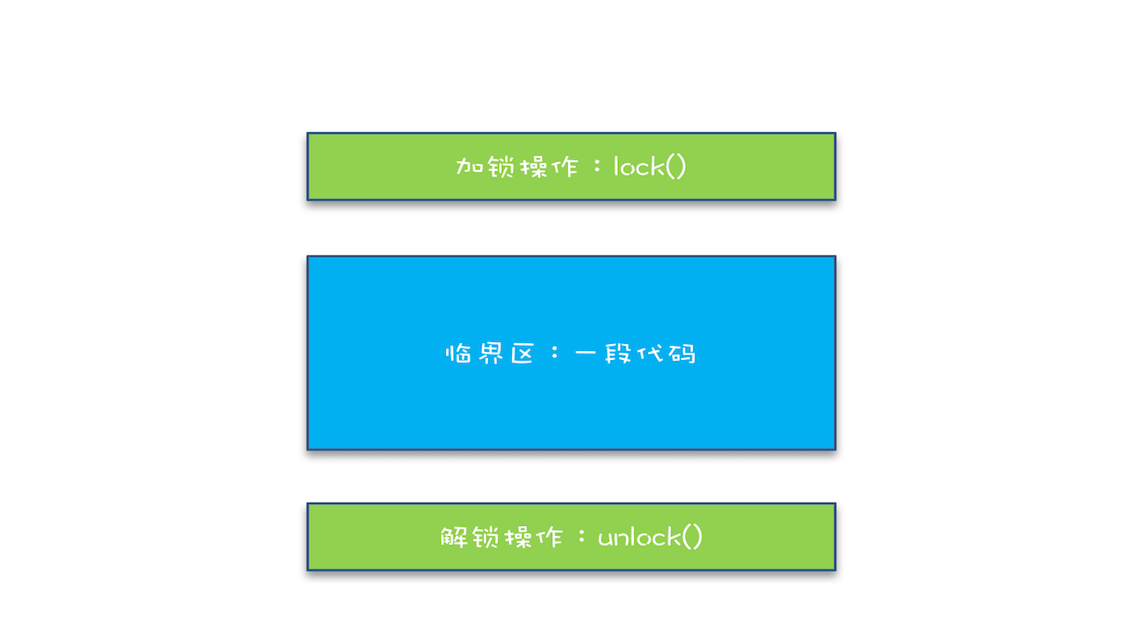
我们把一段需要互斥执行的代码称为临界区,线程在进入临界区之前,首先尝试加锁lock(),如果成功,则进入临界区,此时我们称这个线程持有锁,否则就等待,直到持有锁的线程解锁;持有锁的线程执行完临界区的代码后,执行解锁unlock()。
改进锁模型
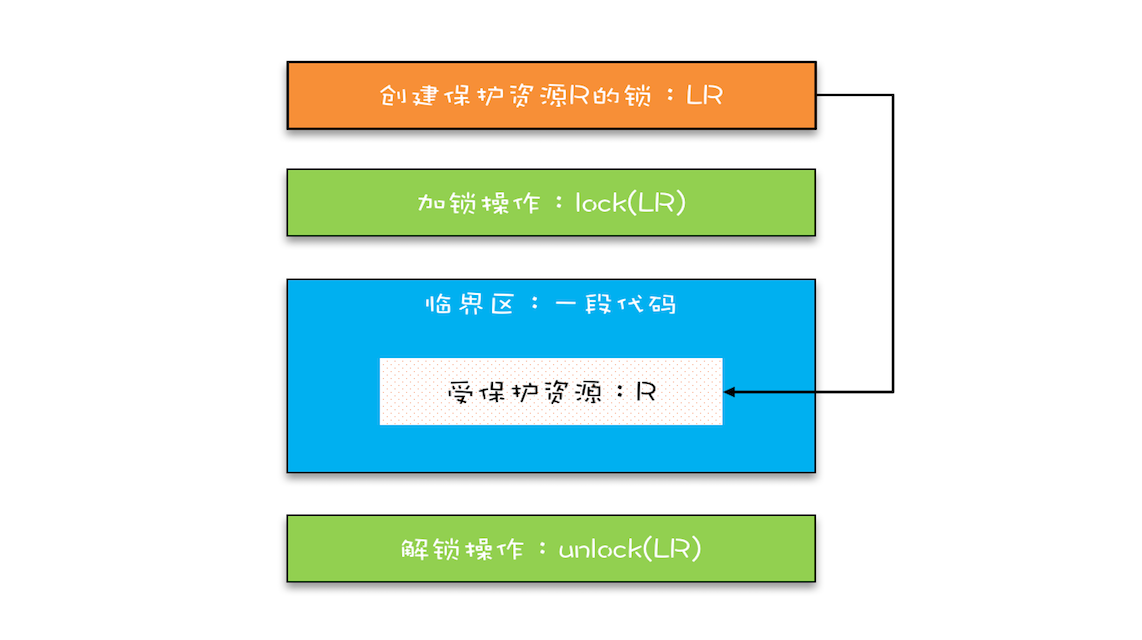
- 把临界区要保护的资源标注出来,如图中临界区里增加了一个元素:受保护的资源 R;
- 保护资源 R 就得为它创建一把锁 LR;
- 针对这把锁 LR,我们还需在进出临界区时添上加锁操作和解锁操作。
在锁 LR 和受保护资源之间,我特地用一条线做了关联,这个关联关系非常重要。很多并发 Bug 的出现都是因为把它忽略了,然后就出现了类似锁自家门来保护他家资产的事情,这样的 Bug 非常不好诊断,因为潜意识里我们认为已经正确加锁了。
Java语言提供的锁技术:synchronized
可以用来修饰方法、也可以修饰代码块
1 | class X { |
可能从这些用法中我们没有发现lock()和unlock(),这两个操作是被Java自动默认加上的,在synchronized修饰的方法或代码块前后自动加上lock()和unlock() ,好处是一定是成对出现的,忘记unlock()比较致命,容易导致线程一直等待。
那么synchronized里的加锁 lock() 和解锁 unlock() 锁定的对象在哪里呢?
上面的代码我们看到只有修饰代码块的时候,锁定了一个 obj 对象,那修饰方法的时候锁定的是什么呢?这个也是 Java 的一条隐式规则:
- 当修饰静态方法的时候,锁定的是当前类的 Class 对象,在上面的例子中就是 Class X;
- 当修饰非静态方法的时候,锁定的是当前实例对象 this。
对于上面的例子,synchronized修饰静态方法相当于:
1 |
|
修饰非静态方法,相当于:
1 |
|
用synchronized解决count+=1的问题
SafeCalc这个类有两个方法:
- get方法,获得value
- addOne方法,给value加1,并且用synchronized修饰
1 |
|
addOne方法首先被肯定的是被修饰后,无论是单核还是多核,只有一个线程能够执行addOne方法,所以一定能保证原子性操作,那是否有可见性问题呢?
我们记得管程中锁的规则:对一个锁的解锁 Happens-Before 于后续对这个锁的加锁。
管程,就是我们这里提到的synchronized,我们知道synchronized修饰的临界区是互斥的,也就是说同一时刻只有一个线程执行临界区的代码;而所谓“对一个锁解锁Happens-Before后续对这个锁的加锁“,指的是前一个线程的解锁操作对后一个线程的加锁操作可见,综合 Happens-Before 的传递性原则,我们就能得出前一个线程在临界区修改的共享变量(该操作在解锁之前),对后续进入临界区(该操作在加锁之后)的线程是可见的。
按照这个规则,如果多个线程同时执行 addOne() 方法,可见性是可以保证的,也就说如果有 1000 个线程执行 addOne() 方法,最终结果一定是 value 的值增加了 1000。看到这个结果,我们长出一口气,问题终于解决了。
但也许,你一不小心就忽视了 get() 方法。执行 addOne() 方法后,value 的值对 get() 方法是可见的吗?这个可见性是没法保证的。管程中锁的规则,是只保证后续对这个锁的加锁的可见性,而 get() 方法并没有加锁操作,所以可见性没法保证。那如何解决呢?很简单,就是 get() 方法也 synchronized 一下,完整的代码如下所示。
1 |
|
上面的代码转换为我们提到的锁模型,就是下面图示这个样子。get() 方法和 addOne() 方法都需要访问 value 这个受保护的资源,这个资源用 this 这把锁来保护。线程要进入临界区 get() 和 addOne(),必须先获得 this 这把锁,这样 get() 和 addOne() 也是互斥的。
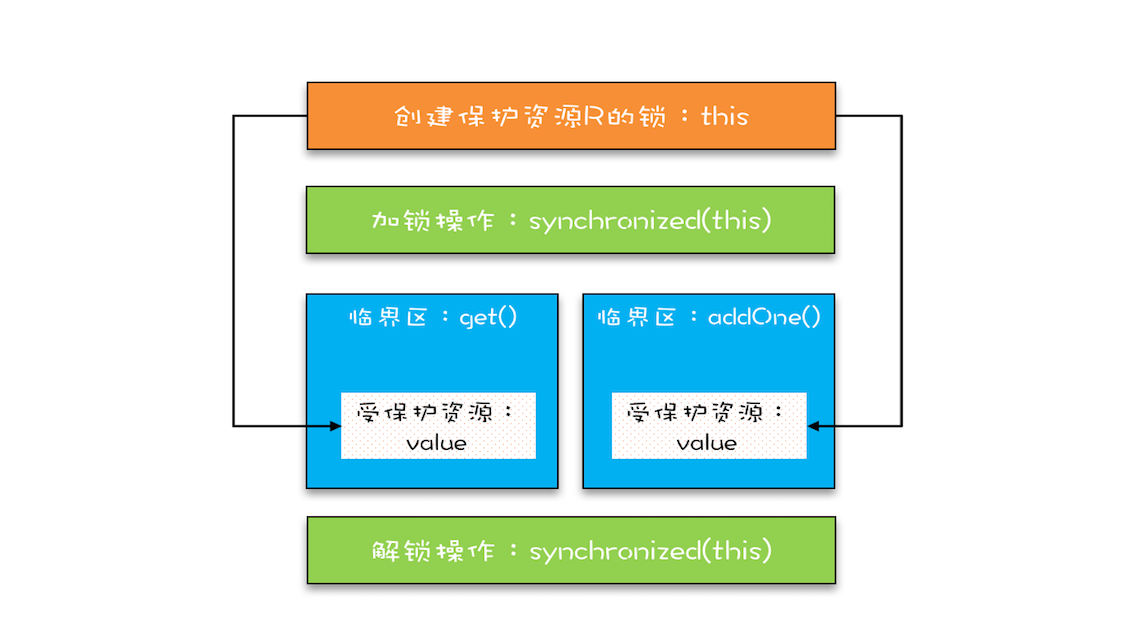
这个模型更像现实世界里面球赛门票的管理,一个座位只允许一个人使用,这个座位就是“受保护资源”,球场的入口就是 Java 类里的方法,而门票就是用来保护资源的“锁”,Java 里的检票工作是由 synchronized 解决的。
锁和受保护资源的关系
受保护资源和锁之间的关联关系是 N:1 的关系
拿前面球赛门票的管理来类比,就是一个座位,我们只能用一张票来保护,如果多发了重复的票,那就要打架了。现实世界里,我们可以用多把锁来保护同一个资源,但在并发领域是不行的,并发领域的锁和现实世界的锁不是完全匹配的。不过倒是可以用同一把锁来保护多个资源,这个对应到现实世界就是我们所谓的“包场”了。
接着上面的那个例子稍作改动,把 value 改成静态变量,把 addOne() 方法改成静态方法,此时 get() 方法和 addOne() 方法是否存在并发问题呢?
1 |
|
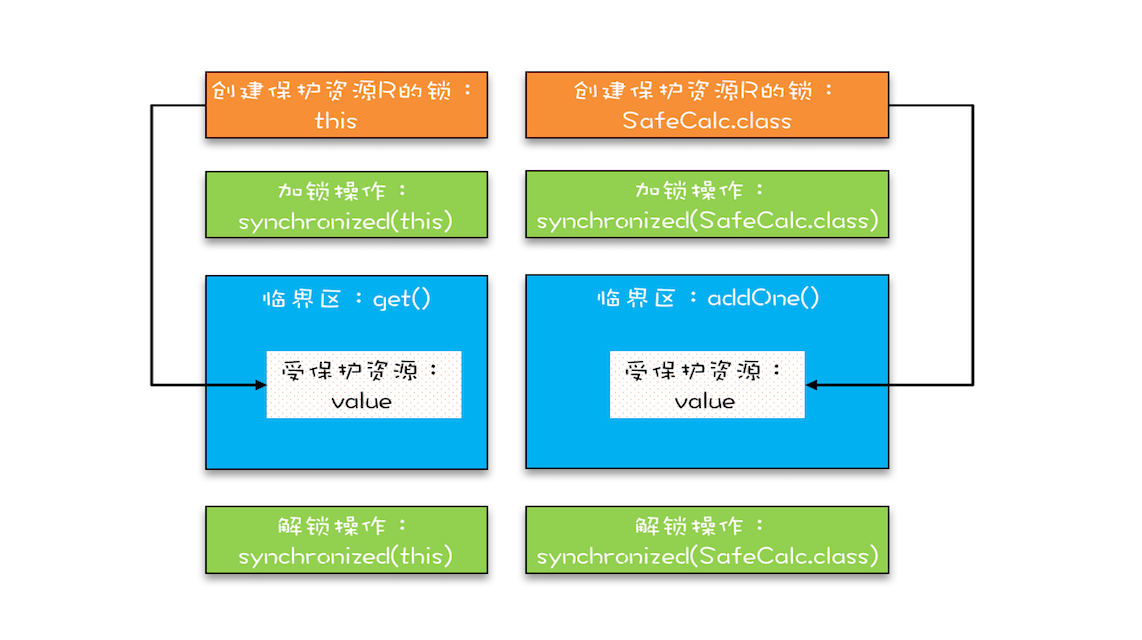
如果你仔细观察,就会发现改动后的代码是用两个锁保护一个资源。这个受保护的资源就是静态变量 value,两个锁分别是 this 和 SafeCalc.class。我们可以用下面这幅图来形象描述这个关系。由于临界区 get() 和 addOne() 是用两个锁保护的,因此这两个临界区没有互斥关系,临界区 addOne() 对 value 的修改对临界区 get() 也没有可见性保证,这就导致并发问题了。
锁保护了资源,同时锁和资源是有对应关系的,所以从资源出发,也可以区分两把锁是不是同一个。 参见下一节课的笔记,可以看出Java里没有单独的锁类型,锁就是用一个对象来表示的,锁和被保护资源之间的对应关系是靠代码逻辑实现的。
Conclusion
并发问题首要想到的解决办法还是加锁,因为加锁能够保证执行临界区代码的互斥性。
真正用好互斥锁: 临界区的代码是操作受保护资源的路径,类似于球场的入口,入口一定要检票,也就是要加锁,但不是随便一把锁都能有效。所以必须深入分析锁定的对象和受保护资源的关系,综合考虑受保护资源的访问路径,多方面考量才能用好互斥锁。
synchronized 是 Java 在语言层面提供的互斥原语,其实 Java 里面还有很多其他类型的锁,但作为互斥锁,原理都是相通的:锁,一定有一个要锁定的对象,至于这个锁定的对象要保护的资源以及在哪里加锁 / 解锁,就属于设计层面的事情了。
问题
1 | class SafeCalc { |
synchronized这个使用方式正确吗?有哪些问题呢?能解决可见性和原子性问题吗?
- 加锁的本质就是在锁对象的对象头中写入当前线程id,但是new object每次在内存中都是新对象,所以加锁无效
- 经过JVM逃逸分析的优化后,这段代码会被直接优化掉,所以在运行时是无锁的
- sync锁的对象monitor指针指向一个ObjectMonitor对象,所有线程加入他的entrylist里面,去cas抢锁,更改state加1拿锁,执行完代码,释放锁state减1,和aqs机制差不多,只是所有线程不阻塞,cas抢锁,没有队列,属于非公平锁。wait的时候,线程进waitset休眠,等待notify唤醒
- 多把锁保护同一个资源,就像一个厕所坑位,有N多门可以进去,没有丝毫保护效果,管理员一看,还不如把门都撤了,弄成开放式(编译器代码优化)😂。
- 两把不同的锁,不能保护临界资源。而且这种new出来只在一个地方使用的对象,其它线程不能对它解锁,这个锁会被编译器优化掉。和没有syncronized代码块效果是相同的
- 不能,因为new了,所以不是同一把锁。老师您好,我对那 synchronized的理解是这样,它并不能改变CPU时间片切换的特点,只是当其他线程要访问这个资源时,发现锁还未释放,所以只能在外面等待,不知道理解是否正确
1 | public class A implements Runnable { |
如何用一把锁保护多个资源?
前面我们提到,可以用一把锁来保护多个资源,但是不能用多把锁来保护一个资源。
当我们要保护多个资源时,首先要区分这些资源是否存在关联关系。
保护没有关联关系的多个资源
在现实世界里,球场的座位和电影院的座位就是没有关联关系的,这种场景非常容易解决,那就是球赛有球赛的门票,电影院有电影院的门票,各自管理各自的。
账户类 Account 有两个成员变量,分别是账户余额 balance 和账户密码 password。取款 withdraw() 和查看余额 getBalance() 操作会访问账户余额 balance,我们创建一个 final 对象 balLock 作为锁(类比球赛门票);而更改密码 updatePassword() 和查看密码 getPassword() 操作会修改账户密码 password,我们创建一个 final 对象 pwLock 作为锁(类比电影票)。不同的资源用不同的锁保护,各自管各自的,很简单。
1 |
|
当然,我们也可以用一把互斥锁来保护多个资源,例如我们可以用 this 这一把锁来管理账户类里所有的资源:账户余额和用户密码。具体实现很简单,示例程序中所有的方法都增加同步关键字 synchronized 就可以了。
但是用一把锁有个问题,就是性能太差,会导致取款、查看余额、修改密码、查看密码这四个操作都是串行的。而我们用两把锁,取款和修改密码是可以并行的。用不同的锁对受保护资源进行精细化管理,能够提升性能。这种锁还有个名字,叫细粒度锁。
保护有关联关系的多个资源
如果多个资源是有关联关系的,那这个问题就有点复杂了。例如银行业务里面的转账操作,账户 A 减少 100 元,账户 B 增加 100 元。这两个账户就是有关联关系的。那对于像转账这种有关联关系的操作,我们应该怎么去解决呢?
先把这个问题代码化。我们声明了个账户类:Account,该类有一个成员变量余额:balance,还有一个用于转账的方法:transfer(),然后怎么保证转账操作 transfer() 没有并发问题呢?
1 | class Account { |
直觉告诉我,用户synchronized关键字修饰以下transfer()方法就可以,于是:
1 | class Account { |
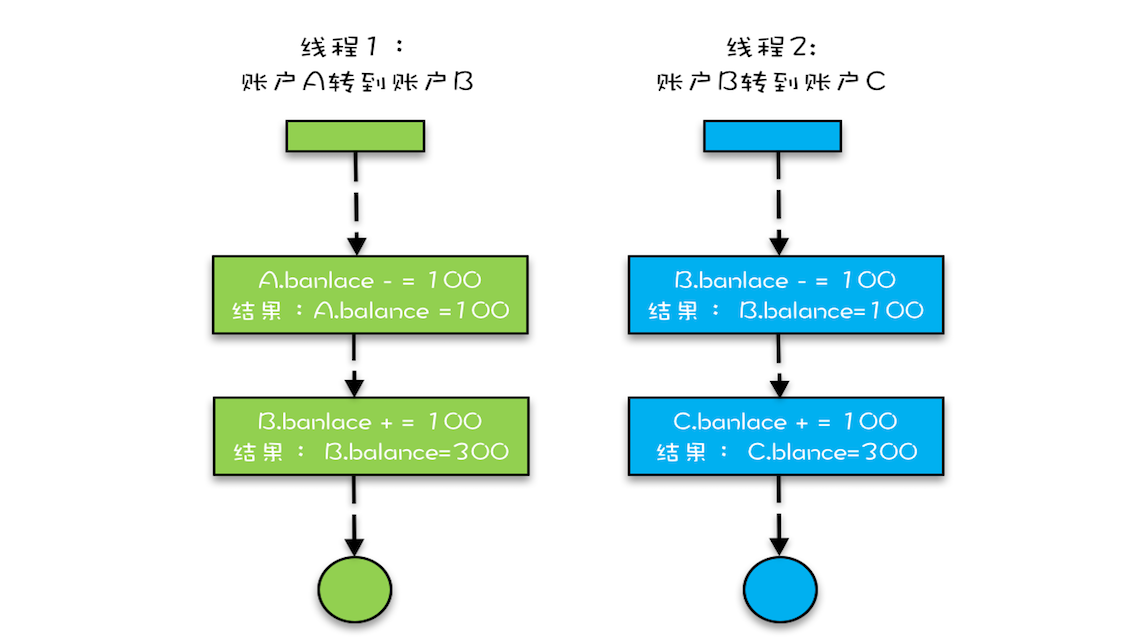
在这段代码中,临界区内有两个资源,分别是转出账户的余额 this.balance 和转入账户的余额 target.balance,并且用的是一把锁 this,符合我们前面提到的,多个资源可以用一把锁来保护。
但是,真的是这样吗?
看似正确,问题就出在this这把锁上,this这把锁可以保护自己的余额this.balance,却保护不了别人的余额target.balance,不能用自家的锁来保护被人家的资产。
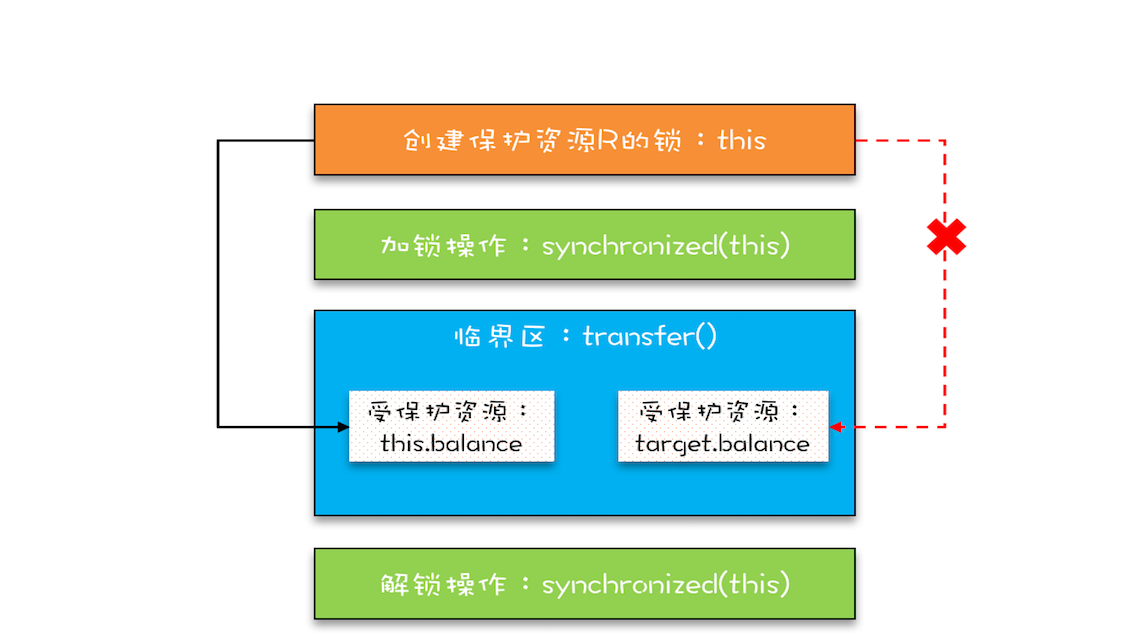
假设有 A、B、C 三个账户,余额都是 200 元,我们用两个线程分别执行两个转账操作:账户 A 转给账户 B 100 元,账户 B 转给账户 C 100 元,最后我们期望的结果应该是账户 A 的余额是 100 元,账户 B 的余额是 200 元, 账户 C 的余额是 300 元。
假设线程 1 执行账户 A 转账户 B 的操作,线程 2 执行账户 B 转账户 C 的操作。这两个线程分别在两颗 CPU 上同时执行,那它们是互斥的吗?我们期望是,但实际上并不是。因为线程 1 锁定的是账户 A 的实例(A.this),而线程 2 锁定的是账户 B 的实例(B.this),所以这两个线程可以同时进入临界区 transfer()。同时进入临界区的结果是什么呢?线程 1 和线程 2 都会读到账户 B 的余额为 200,导致最终账户 B 的余额可能是 300(线程 1 后于线程 2 写 B.balance,线程 2 写的 B.balance 值被线程 1 覆盖),可能是 100(线程 1 先于线程 2 写 B.balance,线程 1 写的 B.balance 值被线程 2 覆盖),就是不可能是 200。
使用锁的正确姿势
前面我们提到用同一把锁来保护多个资源,就是包场
只要我们的锁能覆盖所有受保护的资源就可以。
在上面的例子中,this 是对象级别的锁,所以 A 对象和 B 对象都有自己的锁,如何让 A 对象和 B 对象共享一把锁呢?
首先想到的方法是可以让所有对象都持有一个唯一性的对象,这个对象在创建 Account 时传入。我们把 Account 默认构造函数变为 private,同时增加一个带 Object lock 参数的构造函数,创建 Account 对象时,传入相同的 lock,这样所有的 Account 对象都会共享这个 lock 了。
1 | class Account { |
这个办法确实能解决问题,但是有点小瑕疵,要求在创建Account对象的时候必须传入同一个对象,如果创建 Account 对象时,传入的 lock 不是同一个对象,那可就惨了,会出现锁自家门来保护他家资产的荒唐事。在真实的项目场景中,创建 Account 对象的代码很可能分散在多个工程中,传入共享的 lock 真的很难。
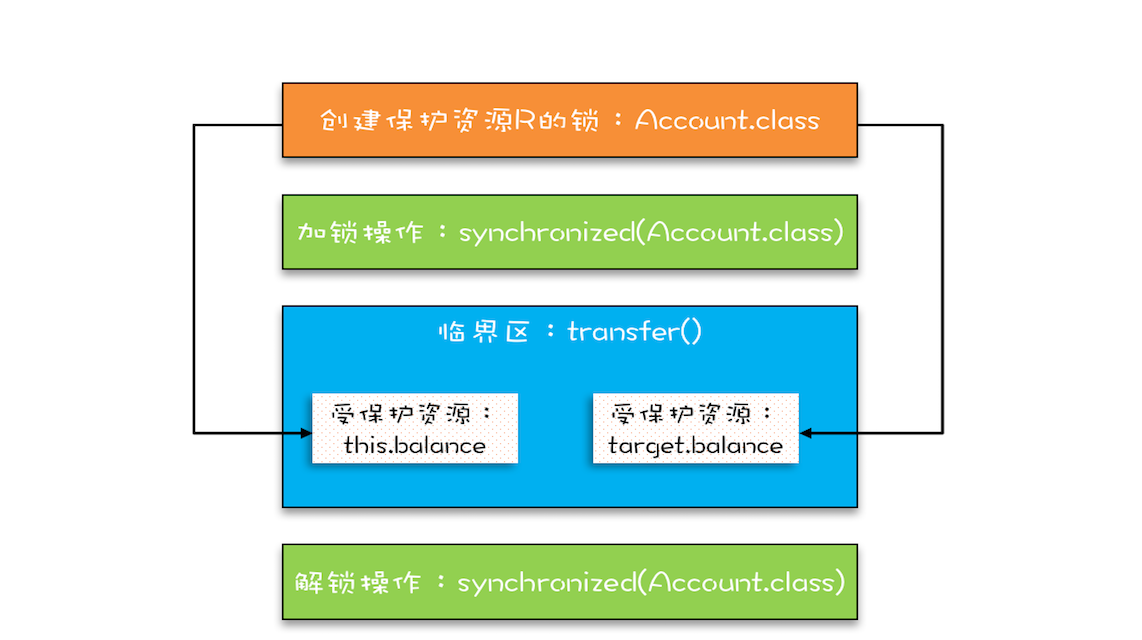
所以,上面的方案缺乏实践的可行性,我们需要更好的方案。还真有,就是用 Account.class 作为共享的锁。Account.class 是所有 Account 对象共享的,而且这个对象是 Java 虚拟机在加载 Account 类的时候创建的,所以我们不用担心它的唯一性。使用 Account.class 作为共享的锁,我们就无需在创建 Account 对象时传入了,代码更简单。
1 | class Account { |
Conclusion
如何保护多个资源关键是要分析多个资源之间的关系。如果资源之间没有关系,很好处理,每个资源一把锁就可以了。如果资源之间有关联关系,就要选择一个粒度更大的锁,这个锁应该能够覆盖所有相关的资源。除此之外,还要梳理出有哪些访问路径,所有的访问路径都要设置合适的锁,这个过程可以类比一下门票管理。
关联关系如果用更具体、更专业的语言来描述的话,其实是一种“原子性”特征,在前面的文章中,我们提到的原子性,主要是面向 CPU 指令的,转账操作的原子性则是属于是面向高级语言的,不过它们本质上是一样的。
“原子性”的本质是什么?其实不是不可分割,不可分割只是外在表现,其本质是多个资源间有一致性的要求,操作的中间状态对外不可见。例如,在 32 位的机器上写 long 型变量有中间状态(只写了 64 位中的 32 位),在银行转账的操作中也有中间状态(账户 A 减少了 100,账户 B 还没来得及发生变化)。所以解决原子性问题,是要保证中间状态对外不可见。
问题
Q: 我们用了两把不同的锁来分别保护账户余额、账户密码,创建锁的时候,我们用的是:private final Object xxxLock = new Object();,如果账户余额用 this.balance 作为互斥锁,账户密码用 this.password 作为互斥锁,你觉得是否可以呢?
A: ** **不能用可变对象做锁,用this.balance 和this.password 都不行。在同一个账户多线程访问时候,A线程取款进行this.balance-=amt;时候此时this.balance对应的值已经发生变换,线程B再次取款时拿到的balance对应的值并不是A线程中的,也就是说不能把可变的对象当成一把锁。this.password 虽然说是String修饰但也会改变,所以也不行。
不能用balance和password做为锁对象。这两个对象balance是Integer,password是String都是不可变变对象,一但对他们进行赋值就会变成新的对象,加的锁就失效了
一不小心就死锁了,怎么办?
前面我们用Account.class作为互斥锁,来解决银行业务里面的转账问题,虽然这个方案不存在并发问题,但是所有账户的转账操作都是串行的。
例如账户A转账户B、账户C转账户D这两个转账操作现实世界里是可以并行的。但是在这个方案里却被串行化了,这样的话,性能太差。
试想互联网支付盛行的当下,8 亿网民每人每天一笔交易,每天就是 8 亿笔交易;每笔交易都对应着一次转账操作,8 亿笔交易就是 8 亿次转账操作,也就是说平均到每秒就是近 1 万次转账操作,若所有的转账操作都串行,性能完全不能接受。
那我们就尝试把性能提升一下。
向现实世界要答案
现实世界里,账户转账操作是支持并发的,而且绝对是真正的并行,银行所有的窗口都可以做转账操作。只要我们能仿照现实世界做转账操作,串行的问题就解决了。
想象一个真实场景,古代没有信息化,账户的存在形式真的就是一个账本,而且每个账户都有一个账本,这些账本都统一放在文件架上,银行柜员在给我们做转账时,要去文件架上把转出账本和转入账本都拿到手,然后做转账。这个柜员在拿账本的时候可能遇到以下三种情况:
- 文件架上恰好有转出账本和转入账本,那就同时拿走;
- 如果文件架上只有转出账本和转入账本之一,那这个柜员就先把文件架上有的账本拿到手,同时等着其他柜员把另外一个账本送回来;
- 转出账本和转入账本都没有,那这个柜员就等着两个账本都被送回来。
这个过程用两把锁就实现了,转出账本一把,转入账本另一把,在transfer()方法内部,首先尝试所的那个转出账户this(先把转出账本拿到手),然后尝试锁定转入账户 target(再把转入账本拿到手),只有当两者都成功时,才执行转账操作。
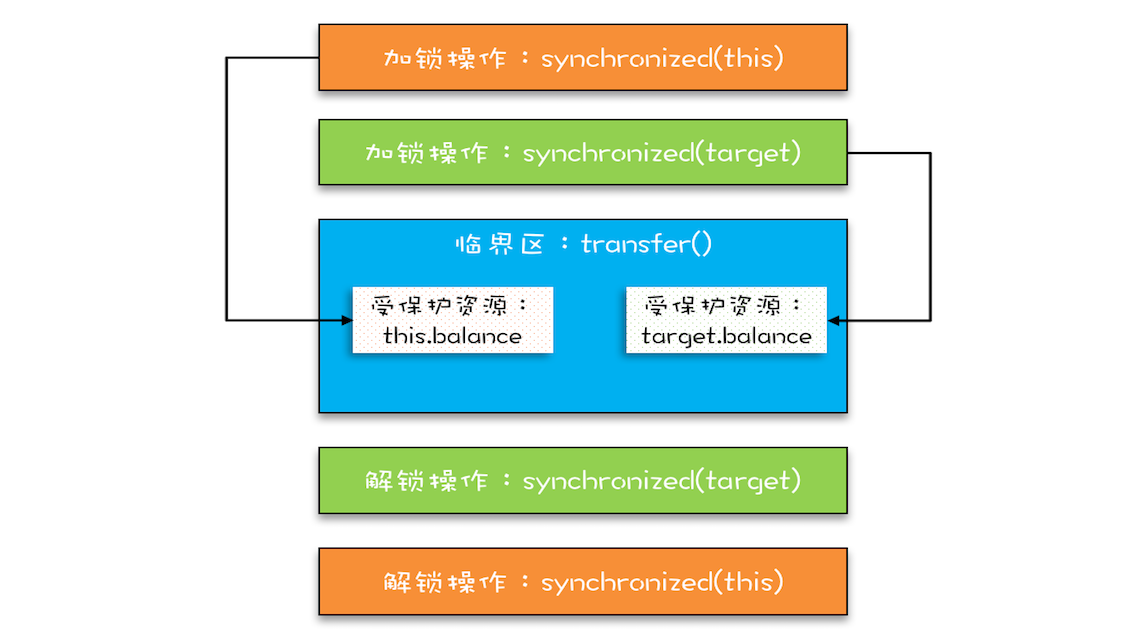
经过这样的优化,账户A转账户B和账户C转账户D这两个转账操作就可以并行了。
1 | class Account { |
没有免费的午餐
上述实现看似很完美,相对于用Account.class作为互斥锁,锁定的范围太大,而我们锁定两个账户范围就小多了,这样的锁,我们称为细粒度锁。
使用细粒度锁可以提高并行度,是性能优化的一个重要手段。
但是,使用细粒度锁是有代价的,这个代价就是可能会导致死锁。
首先我们来看一个特殊场景,如果有客户找柜员张三做个转账业务:账户 A 转账户 B 100 元,此时另一个客户找柜员李四也做个转账业务:账户 B 转账户 A 100 元,于是张三和李四同时都去文件架上拿账本,这时候有可能凑巧张三拿到了账本 A,李四拿到了账本 B。张三拿到账本 A 后就等着账本 B(账本 B 已经被李四拿走),而李四拿到账本 B 后就等着账本 A(账本 A 已经被张三拿走),他们要等多久呢?他们会永远等待下去…因为张三不会把账本 A 送回去,李四也不会把账本 B 送回去。
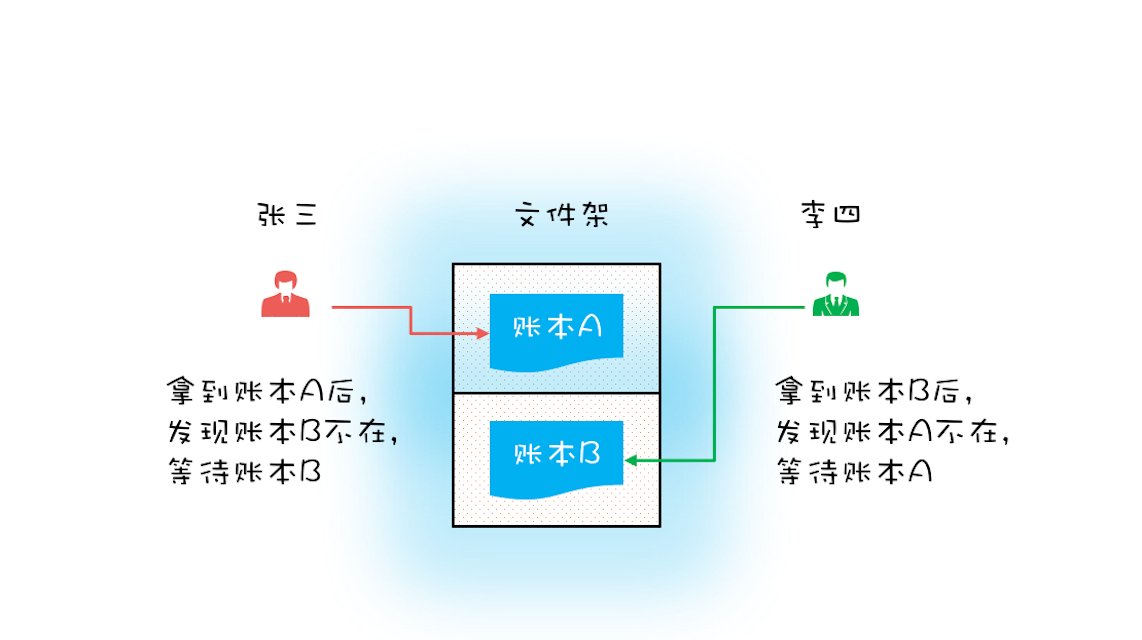
现实世界里的死等,就是编程领域的死锁了。死锁的一个比较专业的定义是:一组互相竞争资源的线程因互相等待,导致“永久”阻塞的现象。
上面转账的代码是怎么发生死锁的呢?我们假设线程 T1 执行账户 A 转账户 B 的操作,账户 A.transfer(账户 B);同时线程 T2 执行账户 B 转账户 A 的操作,账户 B.transfer(账户 A)。当 T1 和 T2 同时执行完①处的代码时,T1 获得了账户 A 的锁(对于 T1,this 是账户 A),而 T2 获得了账户 B 的锁(对于 T2,this 是账户 B)。之后 T1 和 T2 在执行②处的代码时,T1 试图获取账户 B 的锁时,发现账户 B 已经被锁定(被 T2 锁定),所以 T1 开始等待;T2 则试图获取账户 A 的锁时,发现账户 A 已经被锁定(被 T1 锁定),所以 T2 也开始等待。于是 T1 和 T2 会无期限地等待下去,也就是我们所说的死锁了。
1 | class Account { |
关于这种现象,我们还可以借助资源分配图来可视化锁的占用情况(资源分配图是个有向图,它可以描述资源和线程的状态)。
其中,资源用方形节点表示,线程用圆形节点表示;资源中的点指向线程的边表示线程已经获得该资源,线程指向资源的边则表示线程请求资源,但尚未得到。转账发生死锁时的资源分配图就如下图所示,一个“各据山头死等”的尴尬局面。
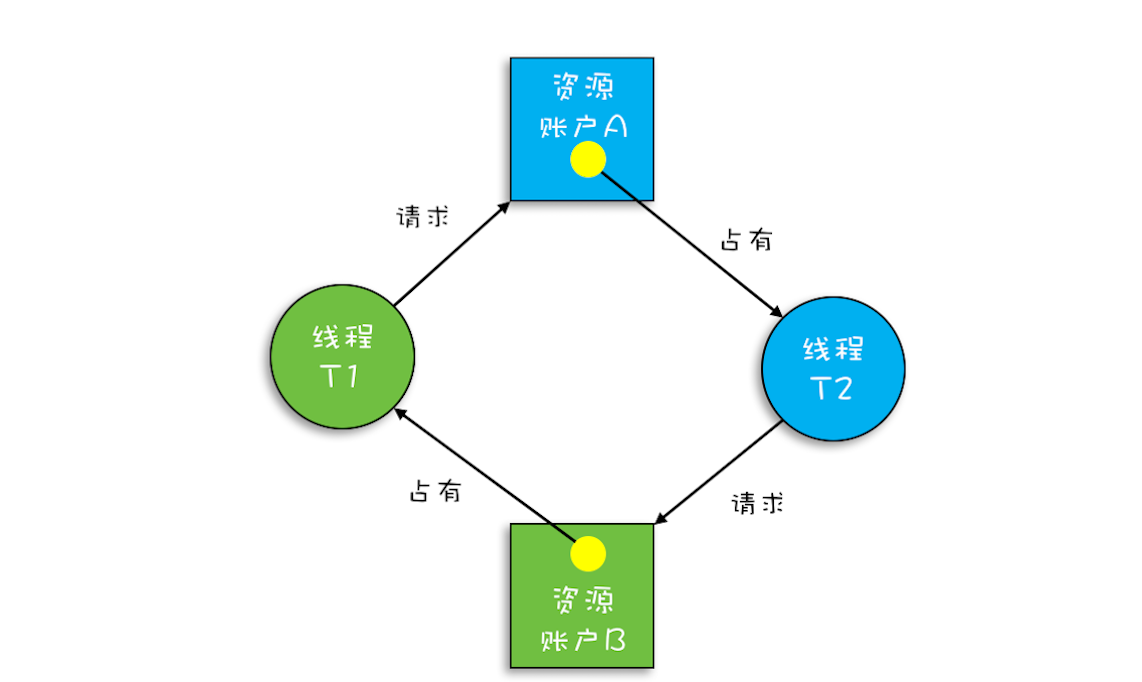
发现了问题,那么
如何预防死锁呢
并发程序一旦死锁,一般没有特别好的方法,很多时候我们只能重启应用。因此,解决死锁问题最好的办法还是规避死锁。
那如何避免死锁呢?要避免死锁就需要分析死锁发生的条件,有个叫 Coffman 的牛人早就总结过了,只有以下这四个条件都发生时才会出现死锁:
- 互斥,共享资源 X 和 Y 只能被一个线程占用;
- 占有且等待,线程 T1 已经取得共享资源 X,在等待共享资源 Y 的时候,不释放共享资源 X;
- 不可抢占,其他线程不能强行抢占线程 T1 占有的资源;
- 循环等待,线程 T1 等待线程 T2 占有的资源,线程 T2 等待线程 T1 占有的资源,就是循环等待。
反过来分析,也就是说只要我们破坏其中一个,就可以成功避免死锁的发生。
其中,互斥这个条件我们没有办法破坏,因为我们用锁为的就是互斥。不过其他三个条件都是有办法破坏掉的,到底如何做呢?
- 对于“占用且等待”这个条件,我们可以一次性申请所有的资源,这样就不存在等待了。
- 对于“不可抢占”这个条件,占用部分资源的线程进一步申请其他资源时,如果申请不到,可以主动释放它占有的资源,这样不可抢占这个条件就破坏掉了。
- 对于“循环等待”这个条件,可以靠按序申请资源来预防。所谓按序申请,是指资源是有线性顺序的,申请的时候可以先申请资源序号小的,再申请资源序号大的,这样线性化后自然就不存在循环了。
破坏占用且等待条件
从理论上讲,要破坏这个条件,可以一次性申请所有资源。在现实世界里,就拿前面我们提到的转账操作来讲,它需要的资源有两个,一个是转出账户,另一个是转入账户,当这两个账户同时被申请时,我们该怎么解决这个问题呢?
可以增加一个账本管理员,然后只允许账本管理员从文件架上拿账本,也就是说柜员不能直接在文件架上拿账本,必须通过账本管理员才能拿到想要的账本。例如,张三同时申请账本 A 和 B,账本管理员如果发现文件架上只有账本 A,这个时候账本管理员是不会把账本 A 拿下来给张三的,只有账本 A 和 B 都在的时候才会给张三。这样就保证了“一次性申请所有资源”。
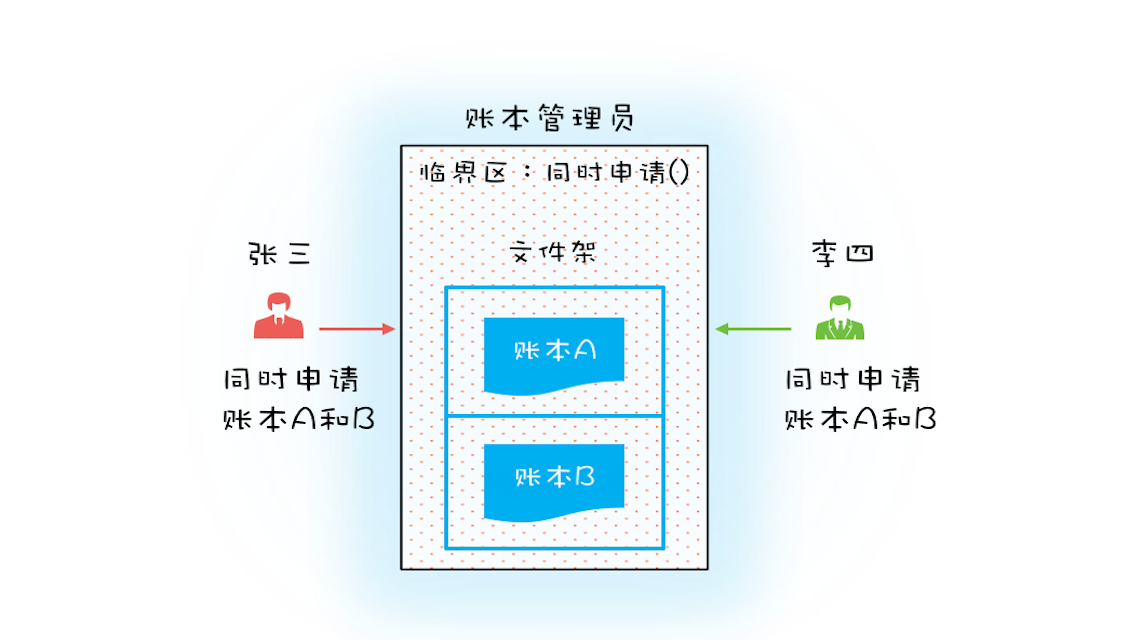
对应到编程领域,“同时申请”这个操作是一个临界区,我们也需要一个角色(Java 里面的类)来管理这个临界区,我们就把这个角色定为 Allocator。它有两个重要功能,分别是:同时申请资源 apply() 和同时释放资源 free()。账户 Account 类里面持有一个 Allocator 的单例(必须是单例,只能由一个人来分配资源)。当账户 Account 在执行转账操作的时候,首先向 Allocator 同时申请转出账户和转入账户这两个资源,成功后再锁定这两个资源;当转账操作执行完,释放锁之后,我们需通知 Allocator 同时释放转出账户和转入账户这两个资源。具体的代码实现如下。
1 | class Allocator { |
破坏不可抢占条件
破坏不可抢占条件看上去很简单,核心是要能够主动释放它占有的资源,这一点 synchronized 是做不到的。原因是 synchronized 申请资源的时候,如果申请不到,线程直接进入阻塞状态了,而线程进入阻塞状态,啥都干不了,也释放不了线程已经占有的资源。
你可能会质疑,“Java 作为排行榜第一的语言,这都解决不了?”你的怀疑很有道理,Java 在语言层次确实没有解决这个问题,不过在 SDK 层面还是解决了的,java.util.concurrent 这个包下面提供的 Lock 是可以轻松解决这个问题的。关于这个话题,咱们后面会详细讲。
破坏循环等待条件
破坏这个条件,需要对资源进行排序,然后按序申请资源。这个实现非常简单,我们假设每个账户都有不同的属性 id,这个 id 可以作为排序字段,申请的时候,我们可以按照从小到大的顺序来申请。比如下面代码中,①~⑥处的代码对转出账户(this)和转入账户(target)排序,然后按照序号从小到大的顺序锁定账户。这样就不存在“循环”等待了。
1 | class Account { |
Conclusion
利用现实世界的模型来构思解决方案
在利用现实模型建模的时候,我们还要仔细对比现实世界和编程世界里的各角色之间的差异。
用细粒度锁来锁定多个资源时,要注意死锁的问题,识别出风险很重要。
预防死锁主要是破坏三个条件中的一个,有了这个思路后,实现就简单了。但仍需注意的是,有时候预防死锁成本也是很高的。例如上面转账那个例子,我们破坏占用且等待条件的成本就比破坏循环等待条件的成本高,破坏占用且等待条件,我们也是锁了所有的账户,而且还是用了死循环 while(!actr.apply(this, target));方法,不过好在 apply() 这个方法基本不耗时。 在转账这个例子中,破坏循环等待条件就是成本最低的一个方案。
所以我们在选择具体方案的时候,还需要评估一下操作成本,从中选择一个成本最低的方案。
问题
破坏占用且等待条件,我们也是锁了所有的账户,而且还是用了死循环 while(!actr.apply(this, target));这个方法,那它比synchronized(Account.class) 有没有性能优势呢?
- synchronized(Account.class) 锁了Account类相关的所有操作。相当于文中说的包场了,只要与Account有关联,通通需要等待当前线程操作完成。while死循环的方式只锁定了当前操作的两个相关的对象。两种影响到的范围不同。
- 最简单的方案: 遇到死锁,我就是用资源id的从小到大的顺序去申请锁解决的
- 用top命令查看Java线程的cpu利用率,用jstack来dump线程。开发环境可以用 java visualvm查看线程执行情况
- while 循环就是一个自旋锁机制吧,自旋锁的话要关注它的循环时间,不能一直循环下去,不然会浪费 cpu 资源。自旋锁在JVM里是一种特殊的锁机制,自诩不会阻塞线程的。咱们这个其实还是会阻塞线程的。不过原理都一样,你这样理解也没问题。
- 最常见的就是B转A的同时,A转账给B,那么先锁B再锁A,但是,另一个线程是先锁A再锁B,然而,如果两个线程同时执行,那么就是出现死锁的情况,线程T1锁了A请求锁B,此时线程T2锁了B请求锁A,都在等着对方释放锁,然而自己都不会释放锁,故死锁。
最简单的办法,就是无论哪个线程执行的时候,都按照顺序加锁,即按照A和B的id大小来加锁,这样,无论哪个线程执行的时候,都会先加锁A,再加锁B,A被加锁,则等待释放。这样就不会被死锁了。
用“等待-通知”机制优化循环等待
上边我们说过,在破坏占用且等待条件的时候,如果转出账本和转入账本不满足同时在文件架上这个条件,就用死循环的方式来循环等待,核心代码如下:
1 | // 一次性申请转出账户和转入账户,直到成功 |
如果 apply() 操作耗时非常短,而且并发冲突量也不大时,这个方案还挺不错的,因为这种场景下,循环上几次或者几十次就能一次性获取转出账户和转入账户了。但是如果 apply() 操作耗时长,或者并发冲突量大的时候,循环等待这种方案就不适用了,因为在这种场景下,可能要循环上万次才能获取到锁,太消耗 CPU 了。
其实在这种场景下,最好的方案应该是:如果线程要求的条件(转出账本和转入账本同在文件架上)不满足,则线程阻塞自己,进入等待状态;当线程要求的条件(转出账本和转入账本同在文件架上)满足后,通知等待的线程重新执行。其中,使用线程阻塞的方式就能避免循环等待消耗 CPU 的问题。
Java 也是支持等待-通知机制的
就医流程
从一个就医流程迁移到一个完整的等待-通知机制的步骤:
线程首先获取互斥锁,当线程要求的条件不满足时,释放互斥锁,进入等待状态;当要求的条件满足时,通知等待的线程,重新获取互斥锁。
用 synchronized 实现等待 - 通知机制
Java 语言里,等待-通知机制可以有多种实现方式,比如 Java 语言内置的 synchronized 配合wait()、notify()、notifyAll() 这三个方法就能轻松实现
那么如何实现:
同一时刻,只允许一个线程进入 synchronized 保护的临界区(这个临界区可以看作大夫的诊室),当有一个线程进入临界区后,其他线程就只能进入图中左边的等待队列里等待(相当于患者分诊等待)。这个等待队列和互斥锁是一对一的关系,每个互斥锁都有自己独立的等待队列。
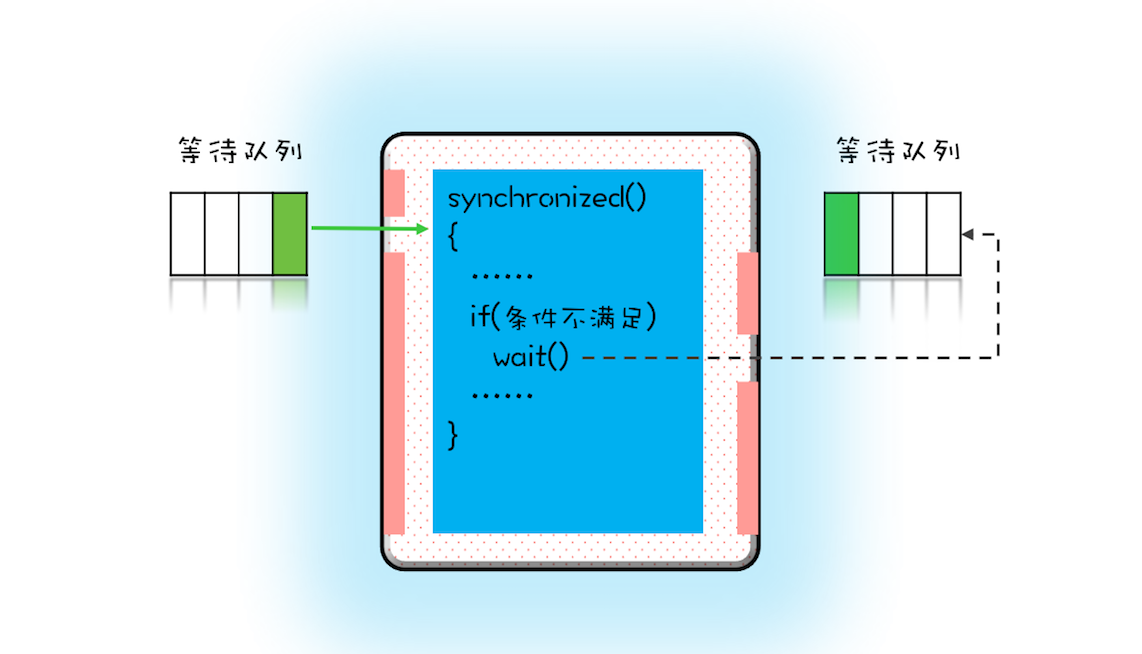
在并发程序中,当一个线程进入临界区后,由于某些条件不满足,需要进入等待状态,Java 对象的 wait() 方法就能够满足这种需求。如上图所示,当调用 wait() 方法后,当前线程就会被阻塞,并且进入到右边的等待队列中,这个等待队列也是互斥锁的等待队列。
线程在进入等待队列的同时,会释放持有的互斥锁,线程释放锁后,其他线程就有机会获得锁,并进入临界区了。
那线程要求的条件满足时,该怎么通知这个等待的线程呢?很简单,就是 Java 对象的 notify() 和 notifyAll() 方法。我在下面这个图里为你大致描述了这个过程,当条件满足时调用 notify(),会通知等待队列(互斥锁的等待队列)中的线程,告诉它条件曾经满足过。
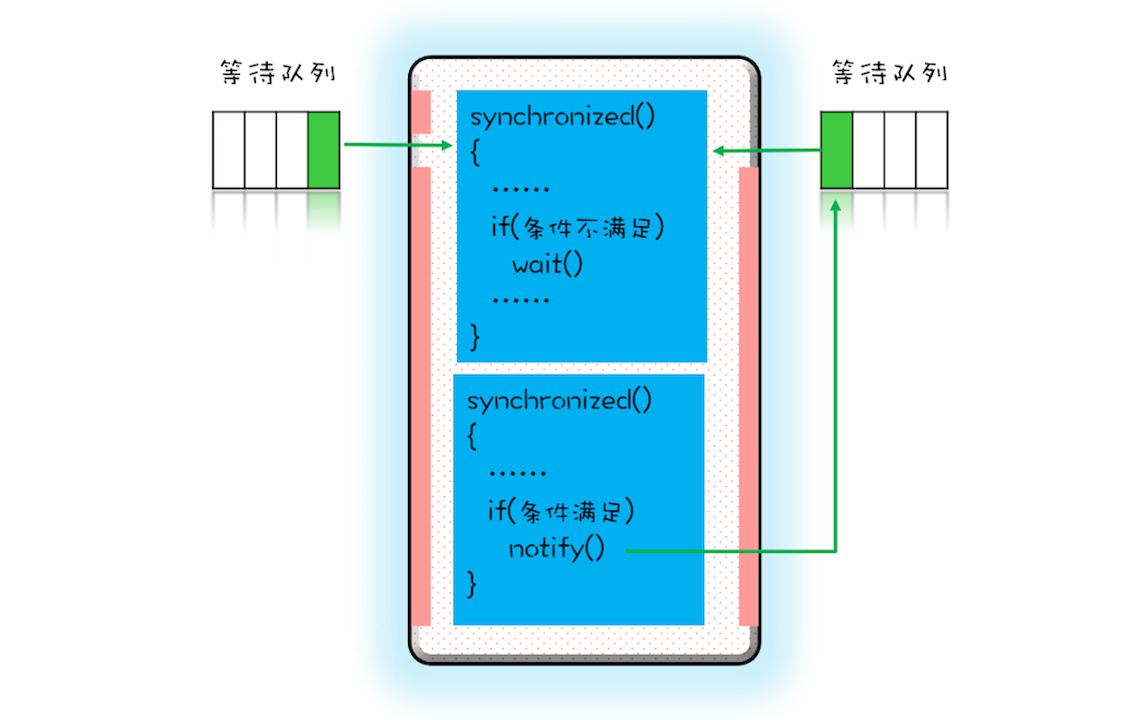
为什么说是曾经满足过呢?因为notify只能保证在通知时间点,条件是满足的。而被通知线程的执行时间点和通知的时间点基本上不会重合,所以当线程执行的时候,很可能条件已经不满足了(保不齐有其他线程插队)。
除此之外,被通知的线程要想重新执行,仍然需要获取到互斥锁(因为曾经获取的锁在调用 wait() 时已经释放了)。
上面我们一直强调 wait()、notify()、notifyAll() 方法操作的等待队列是互斥锁的等待队列,所以如果 synchronized 锁定的是 this,那么对应的一定是 this.wait()、this.notify()、this.notifyAll();如果 synchronized 锁定的是 target,那么对应的一定是 target.wait()、target.notify()、target.notifyAll() 。而且 wait()、notify()、notifyAll() 这三个方法能够被调用的前提是已经获取了相应的互斥锁,所以我们会发现 wait()、notify()、notifyAll() 都是在 synchronized{}内部被调用的。如果在 synchronized{}外部调用,或者锁定的 this,而用 target.wait() 调用的话,JVM 会抛出一个运行时异常:java.lang.IllegalMonitorStateException。
一个更好地资源分配器
搞懂等待-通知机制的基本原理之后,如何解决一次性申请转出账户和转入账户的问题?
需要考虑四个要素:
- 互斥锁,我们之前提到的Allocator需要是单例的,所以我们可以用this作为互斥锁
- 线程要求的条件,转出账户和转入账户都没有被分配过
- 何时等待,线程要求的条件不满足就等待
- 何时通知,当有线程释放账户时就通知
1 |
|
利用这种范式可以解决上面提到的条件曾经满足过这个问题,因为当wait()返回时,有可能条件已经发生变化了,曾经条件满足,但是现在已经不满足了,所以要重新检验条件是否满足,范式,意味着是经典做法。
1 |
|
尽量使用notifyAll()
上面的代码中使用此方法实现通知机制,不使用notify是因为二者是有区别的。
- notify是会随机地通知等待队列中的一个进程
- notifyAll会通知等待队列中的所有线程
从感觉上来讲,应该是 notify() 更好一些,因为即便通知所有线程,也只有一个线程能够进入临界区。但那所谓的感觉往往都蕴藏着风险,实际上使用 notify() 也很有风险,它的风险在于可能导致某些线程永远不会被通知到。
假设我们有资源 A、B、C、D,线程 1 申请到了 AB,线程 2 申请到了 CD,此时线程 3 申请 AB,会进入等待队列(AB 分配给线程 1,线程 3 要求的条件不满足),线程 4 申请 CD 也会进入等待队列。我们再假设之后线程 1 归还了资源 AB,如果使用 notify() 来通知等待队列中的线程,有可能被通知的是线程 4,但线程 4 申请的是 CD,所以此时线程 4 还是会继续等待,而真正该唤醒的线程 3 就再也没有机会被唤醒了。
所以除非经过深思熟虑,否则尽量使用 notifyAll()。
Conclusion
等待 - 通知机制是一种非常普遍的线程间协作的方式。项目中我们经常使用轮询的方式来等待某个状态,其实很多情况下都可以用今天我们介绍的等待 - 通知机制来优化。
Java 语言内置的 synchronized 配合 wait()、notify()、notifyAll() 这三个方法可以快速实现这种机制,但是它们的使用看上去还是有点复杂,所以你需要认真理解等待队列和 wait()、notify()、notifyAll() 的关系。
还是那句话,结合现实,对问题的理解会更深入。
问题
wait方法和sleep方法都能让当前线程挂起一段时间,它们的区别是什么?
- wait会释放所有锁而sleep不会释放锁资源
- wait只能在同步方法和同步块中使用,而sleep任何地方都可以
- wait无需捕捉异常,而sleep需要
wait()方法与sleep()方法的不同之处在于,wait()方法会释放对象的“锁标志”。当调用某一对象的wait()方法后,会使当前线程暂停执行,并将当前线程放入对象等待池中,直到调用了notify()方法后,将从对象等待池中移出任意一个线程并放入锁标志等待池中,只有锁标志等待池中的线程可以获取锁标志,它们随时准备争夺锁的拥有权。当调用了某个对象的notifyAll()方法,会将对象等待池中的所有线程都移动到该对象的锁标志等待池。
sleep()方法需要指定等待的时间,它可以让当前正在执行的线程在指定的时间内暂停执行,进入阻塞状态,该方法既可以让其他同优先级或者高优先级的线程得到执行的机会,也可以让低优先级的线程得到执行机会。但是sleep()方法不会释放“锁标志”,也就是说如果有synchronized同步块,其他线程仍然不能访问共享数据。
到此我们基本认识了并发编程。接下来需要发现并解决一部分问题,以得到更大程度地提升。
发现问题
那么这三个问题就是安全性问题、活跃性问题和性能问题。
安全性问题
我们一定经常听到:“这个方法不是线程安全的”,“这个类不是线程安全的”
什么是线程安全呢?其实本质上就是正确性,正确性的含义就是程序按照我们期望的执行。
如何才能写出线程安全的程序呢?我们在(一)中认知了Bug的三个源头,原子性问题、可见性问题和有序性问题。也就是说,理论上线程安全的程序,就要避免出现这三个问题。
但是并不是所有的代码都需要认真地分析是否存在这三个问题,只有一种情况需要就是,存在共享数据并且该数据会发生变化,通俗地讲就是多个线程会同时读写同一数据。
如果能够做到不共享数据或者数据状态不发生变化,不就能够保证线程的安全性了嘛。有不少技术方案都是基于这个理论的,例如线程本地存储(Thread Local Storage,TLS)、不变模式等等。
现实生活中,必须共享会发生变化的数据。
当多个线程同时访问同一数据,并且至少有一个线程会写这个数据的时候,如果我们不采取防护措施,那么就会导致并发 Bug,对此还有一个专业的术语,叫做数据竞争(Data Race)。
1 | /** |
我们首先想到是不是在访问数据的地方,加个锁保护一下就能解决所有的并发问题了呢,对于上面的示例,增加两个被synchronized修饰的get和set方法,add10k方法里面通过get和set方法来访问value变量。
1 | /** |
假设 count=0,当两个线程同时执行 get() 方法时,get() 方法会返回相同的值 0,两个线程执行 get()+1 操作,结果都是 1,之后两个线程再将结果 1 写入了内存。你本来期望的是 2,而结果却是 1。
这种问题,官方的称呼叫做竞态条件,
所谓竞态条件,指的是程序的执行结果依赖线程执行的顺序。如果两个线程完全同时执行,那么结果是 1;如果两个线程是前后执行,那么结果就是 2。
在并发环境里,线程的执行顺序是不确定的,如果程序存在竞态条件问题,那就意味着程序执行的结果是不确定的,而执行结果不确定这可是个大 Bug。
结合例子说明下竞态条件:前面我们提到过转账操作,有个判断条件就是转出金额不能大于账户金额,但在并发环境里面,如果不加控制,当多个线程同时对一个账号执行转出操作时,就可能出现超额转出问题,假设账户A有月200,线程1和线程2都要从账户A中转出150。
1 | /** |
所以,也可以按照
1 | if (状态变量 满足 执行条件) { |
这样来理解竞态条件,在并发场景中,程序的执行依赖于某个状态变量。
当某个线程发现状态变量满足执行条件后,开始执行操作;可是就在这个线程执行操作的时候,其他线程同时修改了状态变量,导致状态变量不满足执行条件了。
当然很多场景下,这个条件不是显式的,例如前面 addOne 的例子中,set(get()+1) 这个复合操作,其实就隐式依赖 get() 的结果。
Q:面对数据竞争和竞态条件问题,又该如何保证线程的安全性呢?
A:这两类问题,都可以用互斥这个技术方案,而实现互斥的方案有很多,CPU 提供了相关的互斥指令,操作系统、编程语言也会提供相关的 API。从逻辑上来看,我们可以统一归为:锁。
活跃性问题
某个操作无法执行下去,常见的死锁就是一种活跃性问题,当然出了死锁外,还有两种情况,分别是活锁和饥饿。
发生“死锁”后线程会互相等待,而且会一直等待下去,在技术上的表现形式是线程永久地“阻塞”了。
- 活锁:有时线程虽然没有发生阻塞,但仍然会存在执行不下去的情况,这就是所谓的。
- 饥饿:线程因无法访问所需资源而无法执行下去的情况。
- 如果线程优先级“不均”,在 CPU 繁忙的情况下,优先级低的线程得到执行的机会很小,就可能发生线程“饥饿”;持有锁的线程,如果执行的时间过长,也可能导致“饥饿”问题。
解决活锁的方案很简单:尝试等待一个随机事件就可以,简单有效,在Raft分布式一致性算法中用到。
解决饥饿的方案很简单:
- 保证资源充足
- 公平地分配资源
- 避免持有锁的线程长时间执行
1、3的适用场景有限,很多场景下,资源的稀缺性是无法 解决的,持有锁的线程执行的时间也很难缩短,2用的地方更多一些。
Q:如何公平地分配资源呢?
A:并发编程里,主要是使用公平锁。所谓公平锁,是一种先来后到的方案,线程的等待是有顺序的,排在等待队列前面的线程会优先获得资源。
性能问题
使用“锁”要非常小心,但是如果小心过度,也可能出“性能问题”。“锁”的过度使用可能导致串行化的范围过大,这样就不能够发挥多线程的优势了,而我们之所以使用多线程搞并发程序,为的就是提升性能。
所以我们要尽量减少串行,那串行对性能的影响是怎么样的呢?假设串行百分比是 5%,我们用多核多线程相比单核单线程能提速多少呢?
有个阿姆达尔(Amdahl)定律,代表了处理器并行运算之后效率提升的能力,它正好可以解决这个问题,具体公式如下:
$$
S = \frac{1}{(1-p)+\frac{p}{n}}
$$
注:n:CPU核数,p:并行百分比,(1-p):串行百分比
串行比:临界区都是串行的,非临界区都是并行的,用单线程执行临界区的时间/用单线程执行(临界区+非临界区)的时间就是串行百分比。
假设 CPU 的核数(也就是 n)无穷大,那加速比 S 的极限就是 20。也就是说,如果我们的串行率是 5%,那么我们无论采用什么技术,最高也就只能提高 20 倍的性能。
Q:使用锁的时候一定要关注对性能的影响。 那怎么才能避免锁带来的性能问题呢?
A:Java SDK 并发包里之所以有那么多东西,有很大一部分原因就是要提升在某个特定领域的性能。
- 使用无锁的算法和数据结构
- 线程本地存储 (Thread Local Storage, TLS)、写入时复制 (Copy-on-write)、乐观锁等;Java 并发包里面的原子类也是一种无锁的数据结构;Disruptor 则是一个无锁的内存队列…
- 减少锁持有的时间
- 互斥锁本质上是将并行的程序串行化,所以要增加并行度,一定要减少持有锁的时间。
- 使用细粒度的锁,一个典型的例子就是 Java 并发包里的 ConcurrentHashMap,它使用了所谓分段锁的技术(这个技术后面我们会详细介绍);还可以使用读写锁,也就是读是无锁的,只有写的时候才会互斥。
- 互斥锁本质上是将并行的程序串行化,所以要增加并行度,一定要减少持有锁的时间。
性能方面的度量指标有多个,最重要的三个:
- 吞吐量:指的是单位时间内能处理的请求数量。吞吐量越高,说明性能越好;
- 延迟:指的是从发出请求到收到响应的时间。延迟越小,说明性能越好;
- 并发量:指的是能同时处理的请求数量,一般来说随着并发量的增加、延迟也会增加。所以延迟这个指标,一般都会是基于并发量来说的。例如并发量是 1000 的时候,延迟是 50 毫秒。
并发编程是一个复杂的技术领域,
- 微观上涉及到原子性问题、可见性问题和有序性问题,
- 宏观则表现为安全性、活跃性以及性能问题。
我们在设计并发程序的时候,主要是从宏观出发,也就是要重点关注它的安全性、活跃性以及性能。安全性方面要注意数据竞争和竞态条件,活跃性方面需要注意死锁、活锁、饥饿等问题,性能方面我们虽然介绍了两个方案,但是遇到具体问题,你还是要具体分析,根据特定的场景选择合适的数据结构和算法。
要解决问题,首先要把问题分析清楚。同样,要写好并发程序,首先要了解并发程序相关的问题。
思考
Java 语言提供的 Vector 是一个线程安全的容器,检查以下代码是否存在并发问题。
1 | void addIfNotExist(Vector v, |
- vector是线程安全,指的是它方法单独执行的时候没有并发正确性问题,并不代表把它的操作组合在一起问木有,而这个程序显然有竞态条件问题。
- contains和add之间不是原子操作,有可能重复添加。
- Vector实现线程安全是通过给主要的写方法加了synchronized,类似contains这样的读方法并没有synchronized,该题的问题就出在不是线程安全的contains方法,两个线程如果同时执行到if(!v.contains(o)) 是可以都通过的,这时就会执行两次add方法,重复添加。也就是竞态条件问题。