Convolutional Neural Networks
使用全连接层的局限性:
- 图像在同一列邻近的像素在这个向量中可能相距较远。它们构成的模式可能难以被模型识别。
- 对于大尺寸的输入图像,使用全连接层容易导致模型过大。
使用卷积层的优势:
- 卷积层保留输入形状。
- 卷积层通过滑动窗口将同一卷积核与不同位置的输入重复计算,从而避免参数尺寸过大。
卷积神经网络就是含卷积层的网络。
LeNet 模型
90%以上的参数都在全连接层块
LeNet分为卷积层块和全连接层块两个部分
解释:
卷积层块由两个这样的基本单位重复堆叠构成。在卷积层块中,每个卷积层都使用$5 \times 5$的窗口,并在输出上使用sigmoid激活函数。第一个卷积层输出通道数为6,第二个卷积层输出通道数则增加到16。
全连接层块含3个全连接层。它们的输出个数分别是120、84和10,其中10为输出的类别个数。
卷积层块里的基本单位
是卷积层后接平均池化层
卷积层用来识别图像里的空间模式,如线条和物体局部
之后的平均池化层则用来降低卷积层对位置的敏感性。
LeNet交替使用卷积层和最大池化层后接全连接层来进行图像分类
通过 Sequential 类实现 LeNet 模型
1 | #import |
1 | #net |
获取数据
1 | # 数据 |
因为卷积神经网络计算比多层感知机要复杂,建议使用GPU来加速计算。我们查看看是否可以用GPU,如果成功则使用 cuda:0,否则仍然使用 cpu。
1 | # This function has been saved in the d2l package for future use |
训练
计算准确率
1 | ''' |
训练函数
1 | #训练函数 |
训练进程
模型参数初始化到 device 中,并使用 Xavier 随机初始化。损失函数和训练算法则依然使用交叉熵损失函数和小批量随机梯度下降。
Xavier 随机初始化 —参考学而后思,方能发展;思而立行,终将卓越
1 | # 训练 学习率0.9 |
测试
1 | # test |
深度卷积神经网络(AlexNet)
2014年ImgNet竞赛中
证明了学习到的特征可以超过手工设计的特征, 打破计算机视觉研究的前状
LeNet: 在大的真实数据集上的表现并不尽如⼈意。
1.神经网络计算复杂。
2.还没有⼤量深⼊研究参数初始化和⾮凸优化算法等诸多领域。
在此之后,针对特征的选择分为两派:
- 机器学习的特征提取:手工定义的特征提取函数
- 神经网络的特征提取:通过学习得到数据的多级表征,并逐级表⽰越来越抽象的概念或模式。
神经网络发展的限制:数据、硬件
AlexNet
设计理念核Lenet相似
特征:
- 8层变换,其中有5层卷积和2层全连接隐藏层,以及1个全连接输出层。
- 将sigmoid激活函数改成了更加简单的ReLU激活函数。
- 用Dropout来控制全连接层的模型复杂度。
- 引入数据增强,如翻转、裁剪和颜色变化,从而进一步扩大数据集来缓解泛化能力不好导致的过拟合。
$$
数据集.MINIST(Left) IMAGENET(Right)
$$
利用padding 的作用:使得输入和输出的形状相同
可以参考 Fundamentals of Convolutional Neural Networks
1 | import time |
实现 AlexNet 模型
1 | class AlexNet(nn.Module): |
载入数据
1 | def load_data_fashion_mnist(batch_size, resize=None, root='/home/kesci/input/FashionMNIST2065'): |
训练
1 | lr, num_epochs = 0.001, 3 |
使用重复元素的网络(VGG)
AlxNet
并没有提供简单的规则来制造新的网络
结构比较死板
所以 VGG:通过重复使⽤简单的基础块来构建深度模型。
Block:数个相同的填充为1、窗口形状为$3\times 3$的卷积层,接上一个步幅为2、窗口形状为$2\times 2$的最大池化层。
卷积层保持输入的高和宽不变,而池化层则对其减半
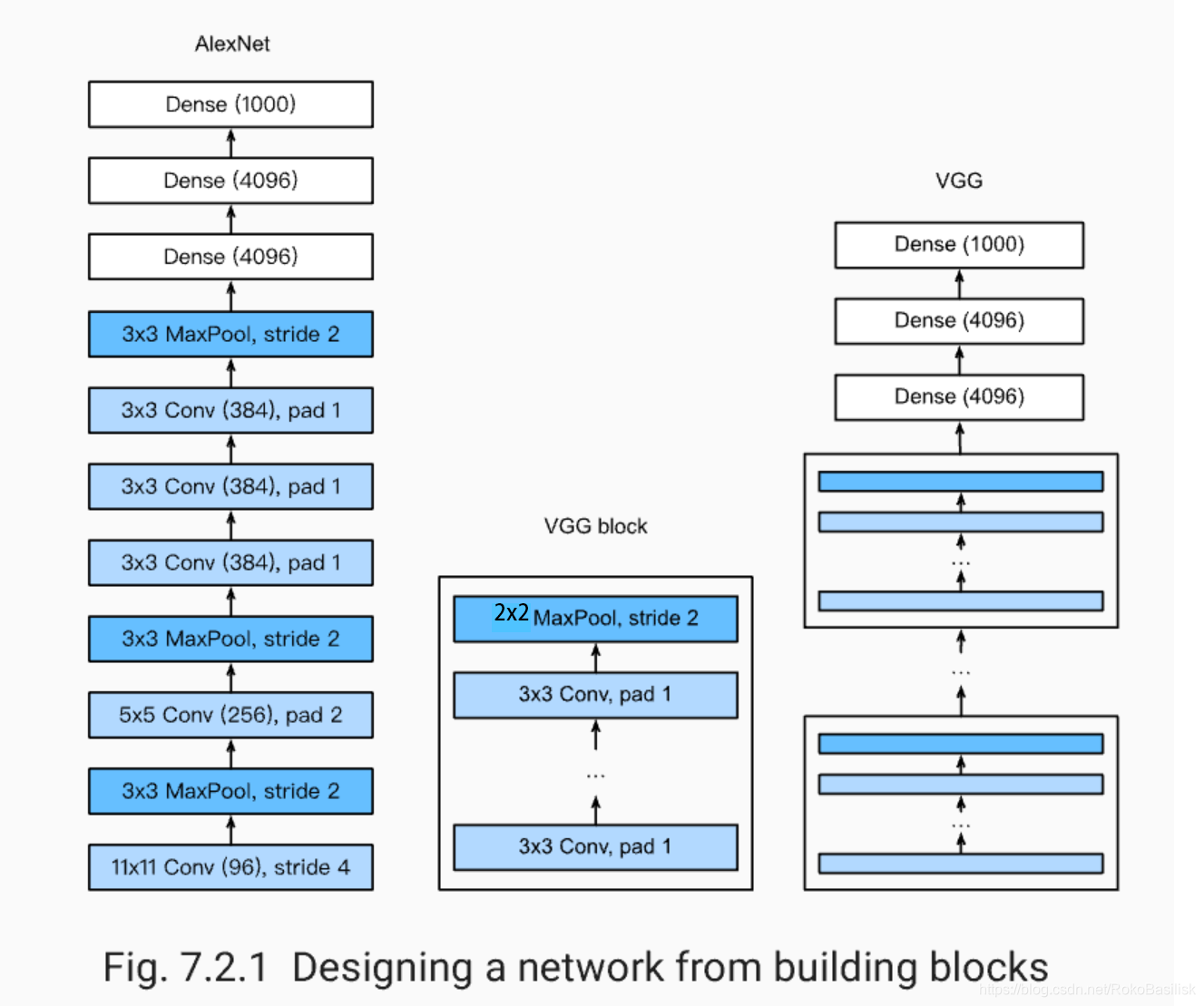
VGG11的实现
1 | # 可以修改的参数 e每个vgg_block结构相同但是参数可能不相同 |
1 | # vgg模型 |
1 | net = vgg(conv_arch, fc_features, fc_hidden_units) |
1 | lr, num_epochs = 0.001, 5 |
网络中的网络(NiN)
LeNet、AlexNet和VGG
先以由卷积层构成的模块充分抽取 空间特征
再以由全连接层构成的模块来输出分类结果
NiN
串联多个由卷积层和 “全连接” 层构成的小⽹络来构建⼀个深层⽹络。
NiN去掉了全连接层,而是用平均池化层
⽤了输出通道数等于标签类别数的NiN块,然后使⽤全局平均池化层对每个通道中所有元素求平均并直接⽤于分类。 这样的设计显著的减少了参数尺寸防止过拟合,但是增加了训练时间
$1\times1$卷积核作用:
- 放缩通道数:通过控制卷积核的数量达到通道数的放缩。
- 增加非线性。1×1卷积核的卷积过程相当于全连接层的计算过程,并且还加入了非线性激活函数,从而可以增加网络的非线性。
- 计算参数少
NiN 的实现
1 | # 构建组成模块nin_block |
1 | class GlobalAvgPool2d(nn.Module): |
1 | batch_size = 128 |
NiN
- NiN重复使⽤由卷积层和代替全连接层的1×1卷积层构成的NiN块来构建深层⽹络 ;
- NiN去除了容易造成过拟合的全连接输出层,而是将其替换成输出通道数等于标签类别数 的NiN块和全局平均池化层 ;
- NiN的以上设计思想影响了后⾯⼀系列卷积神经⽹络的设计 ;
GoogLeNet
牺牲了串联网络的思想
- 由 Inception 基础块组成。
- Inception 块相当于⼀个有4条线路的⼦⽹络。它通过不同窗口形状的卷积层和最⼤池化层来并⾏抽取信息,并使⽤1×1卷积层减少通道数从而降低模型复杂度。
- 可以⾃定义的超参数是每个层的输出通道数,我们以此来控制模型复杂度。
- 使用 padding 来保证输入输出形状相同
Inception 基础块实现
1 | class Inception(nn.Module): |
完整模型结构
$$
input -1\times96\times96
$$
1 | # 抽取特征来减小大小 |